OSPF 路由协议
RIP 协议缺陷
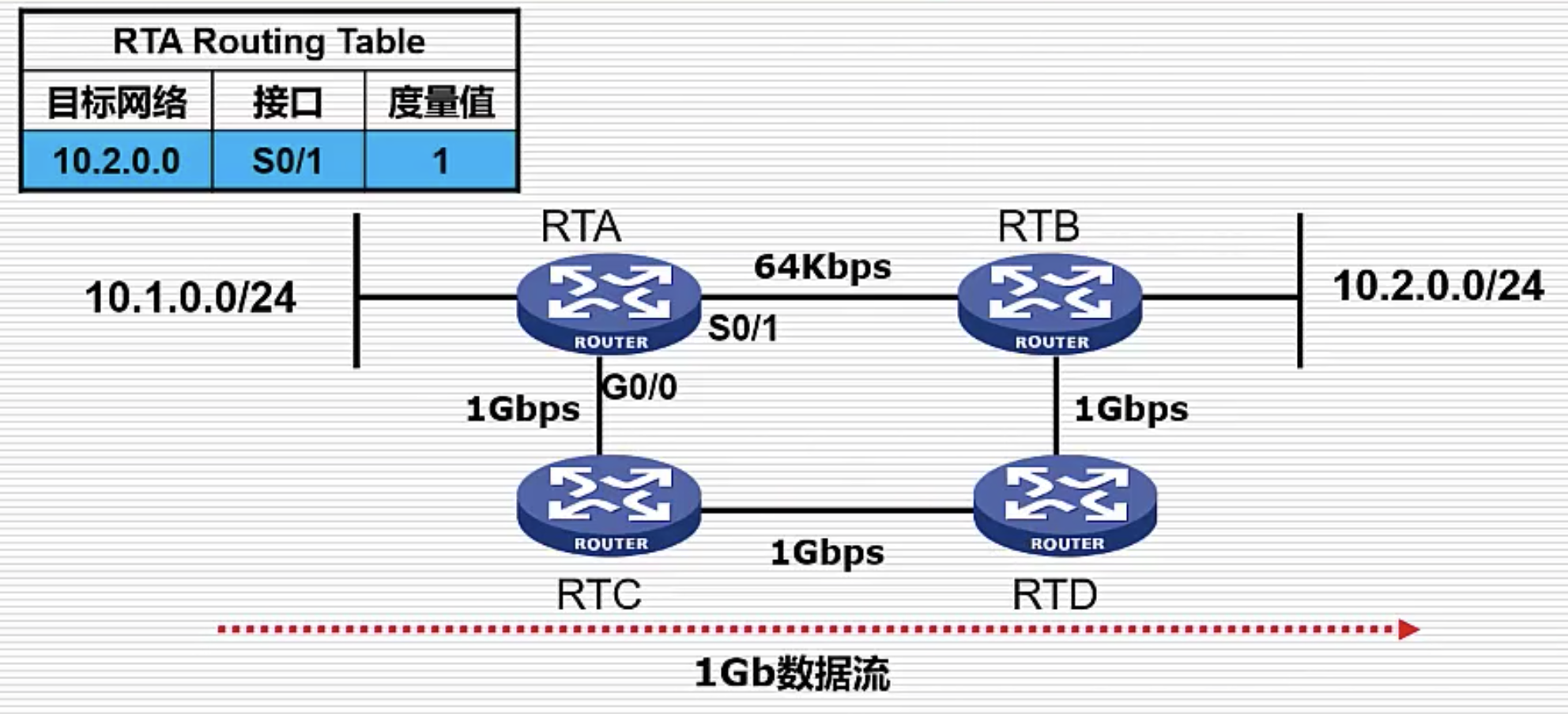
缺陷一:以跳数评估的路由并非最优路径
RIP 路由协议选择跳数最短的路由,在下图中会选择 RTA —> RTB 的路径。
但虽然 RTA —> RTB 的路径跳数最短,但由于带宽的区别,对于大数据流走 RTA —> RTC —> RTD —> RTB 反而快于跳数更短的 RTA —> RTB 路径。
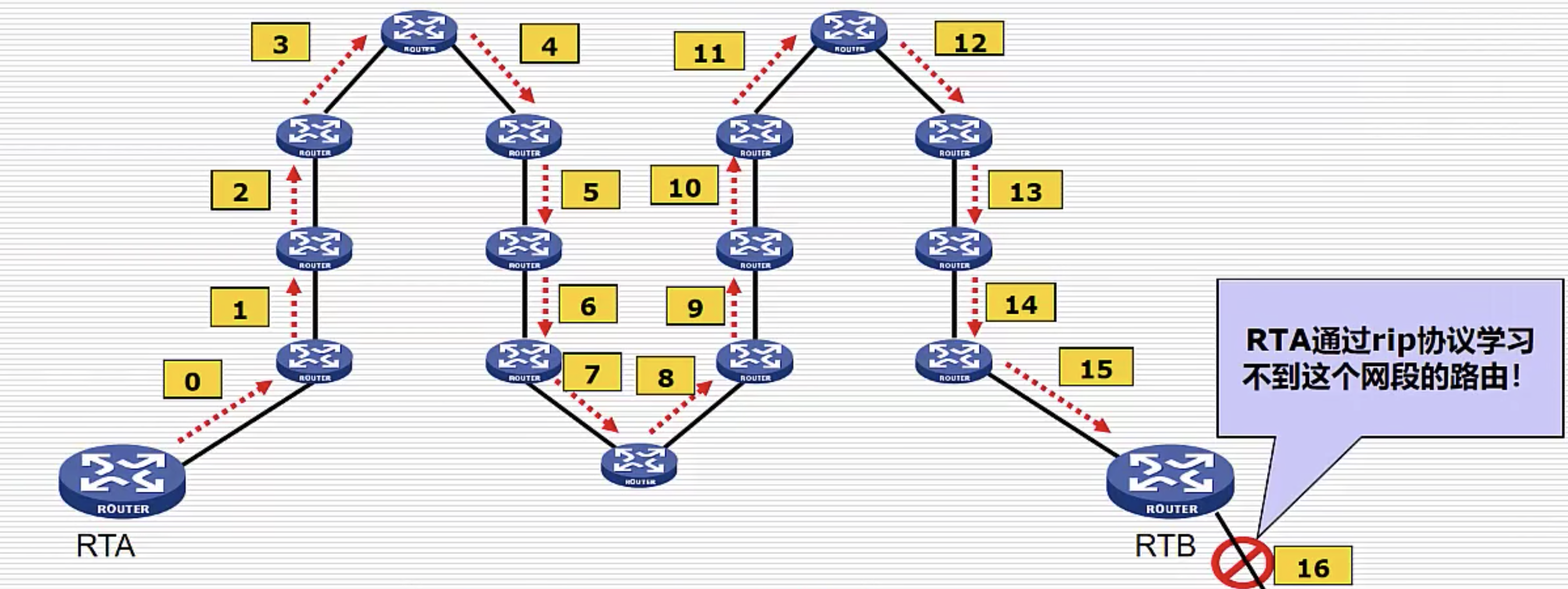
缺陷二:最大跳数15限制网络规模
RIP 允许的跳数最大只有15条,如果跳数大于等于16跳,则会被视为不可达,无法学习到16跳网段的路由,从而限制了网络规模的大小。
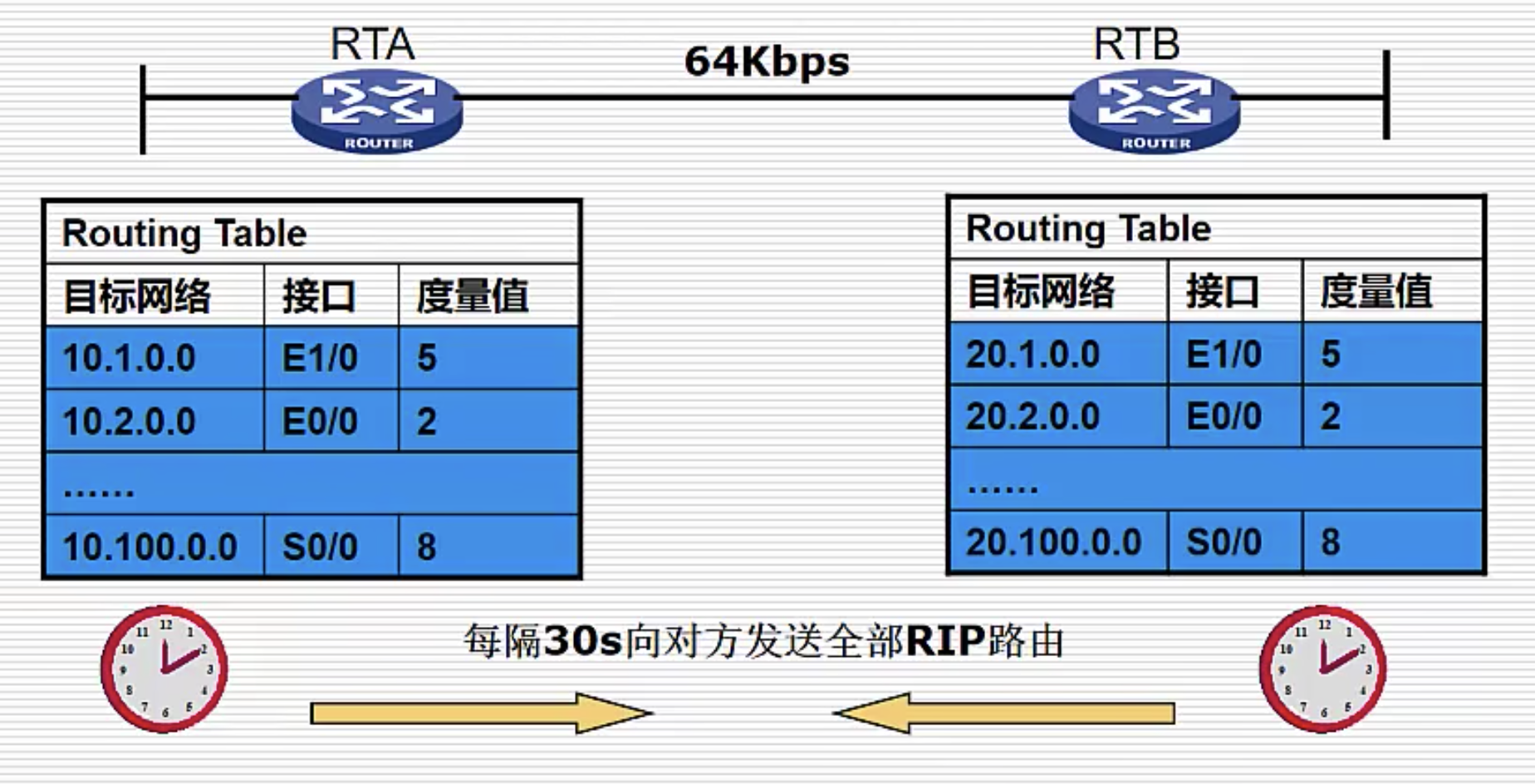
缺陷三:更新路由发送全量路由信息,浪费网络资源
RIP 每隔一段时间,都会向所有邻居发送全量的路由信息,十分消耗网络资源。
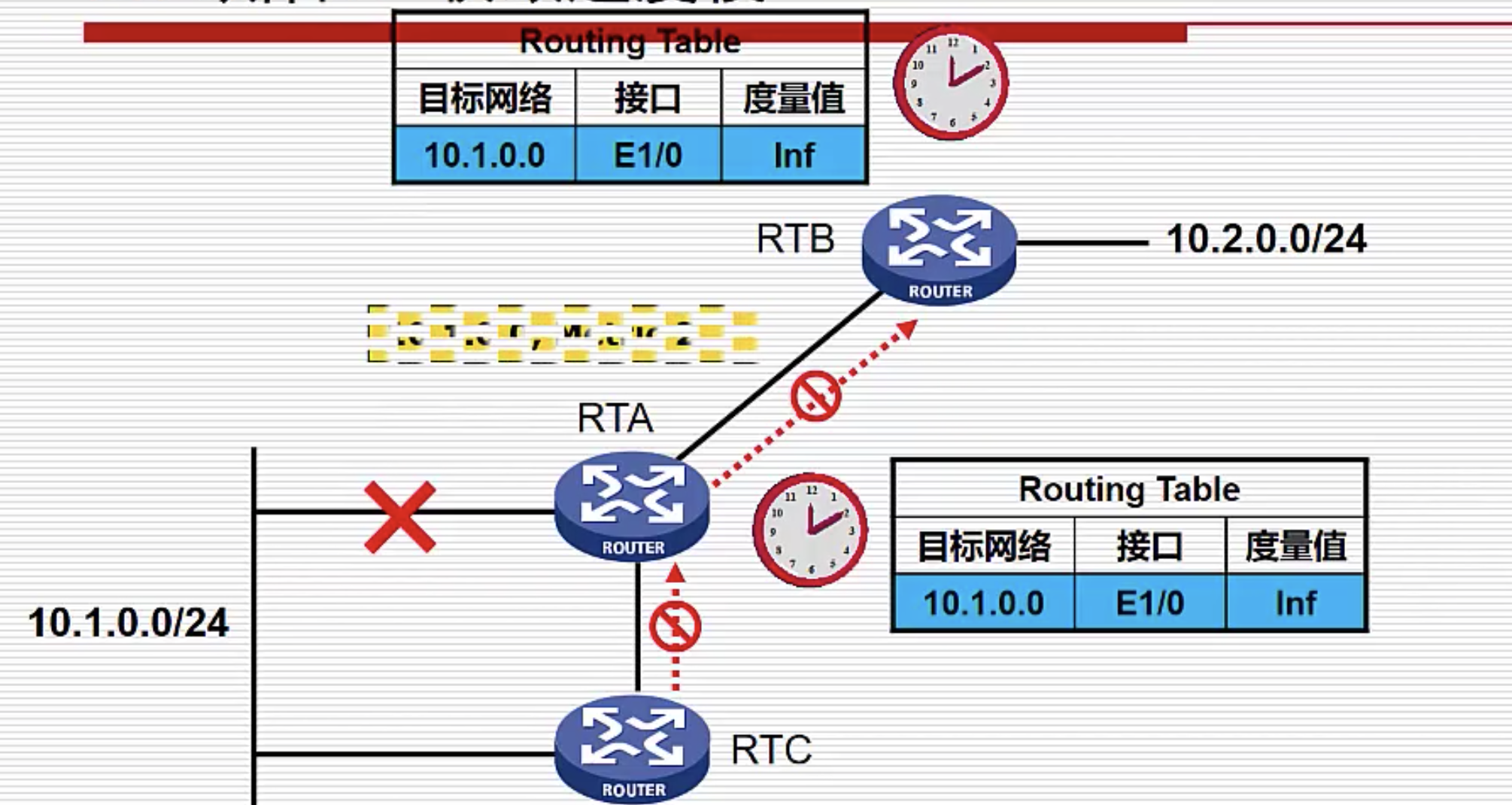
缺陷四:收敛速度慢
OSPF 链路状态路由协议
- 工作在 IP 层,IP 协议号 89
- 以组播地址 224.0.0.5 发送协议包
- 每个路由器将已知的链路状态信息发送给邻居,收敛后,每个路由器对全网链路状态的认识相同,并独立计算自己的路由
OSPF 工作过程
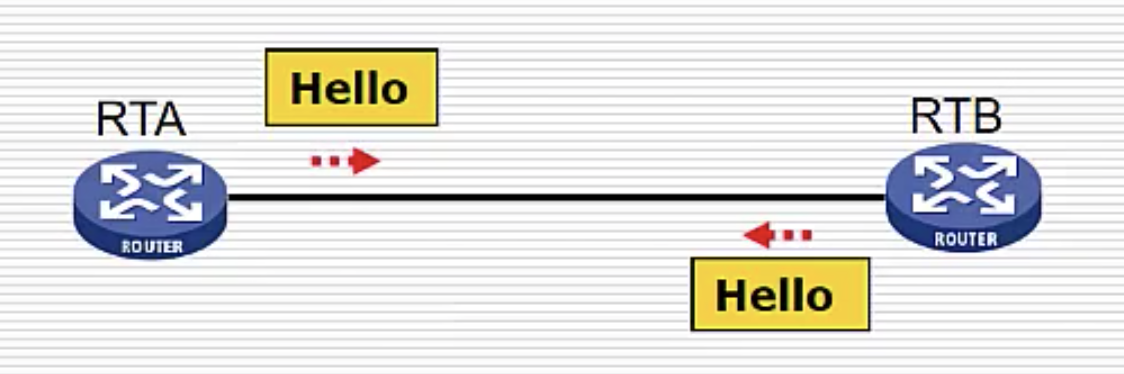
1. 发现邻居
在广播域中组播 hello 包,收到互相的 hello 包,确认是自己的邻居,则加入邻居表中
2. 建立邻接关系
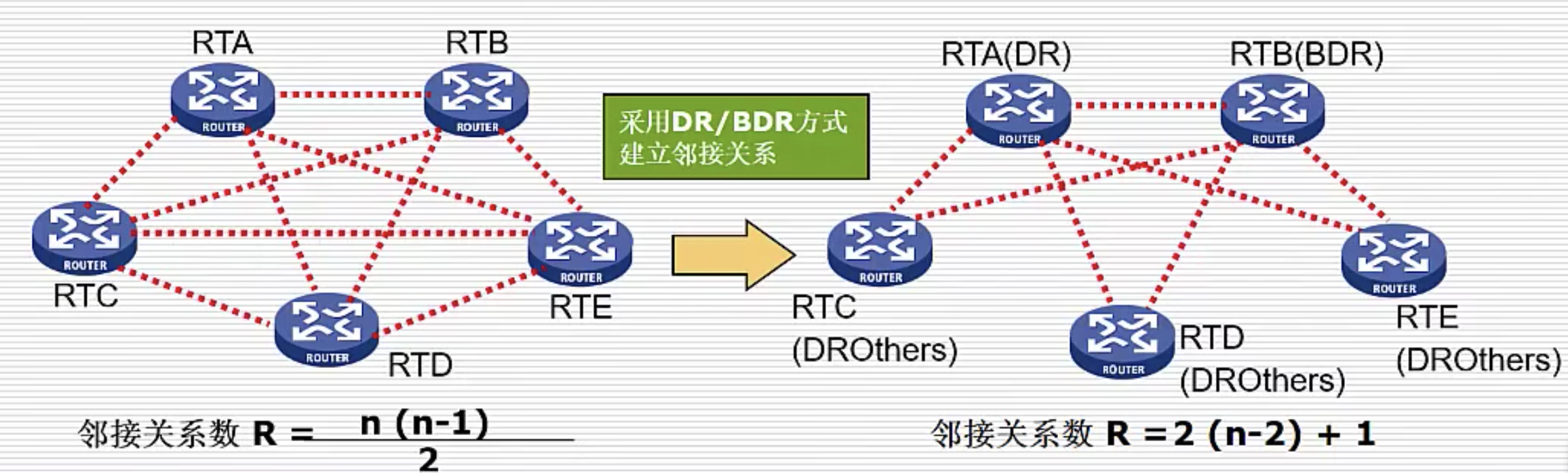
- 并不是所有邻居都会建立邻接关系
- 网段的广播域中会选取 DR 和 BDR(副 DR,用于容灾),剩下的节点都是 DR_Others,该广播域中的所有路由器都只与 DR 和 BDR 建立邻接关系
- 只有和建立了邻接关系的邻居才会交换链路状态信息
- 只有在广播型网络中才会使用 DR 和 BDR,点到点(PPP,即一对一)不使用 DR 和 BDR
如此,可以减少交换信息的次数,路由更新更高效
3. 传递链路状态信息
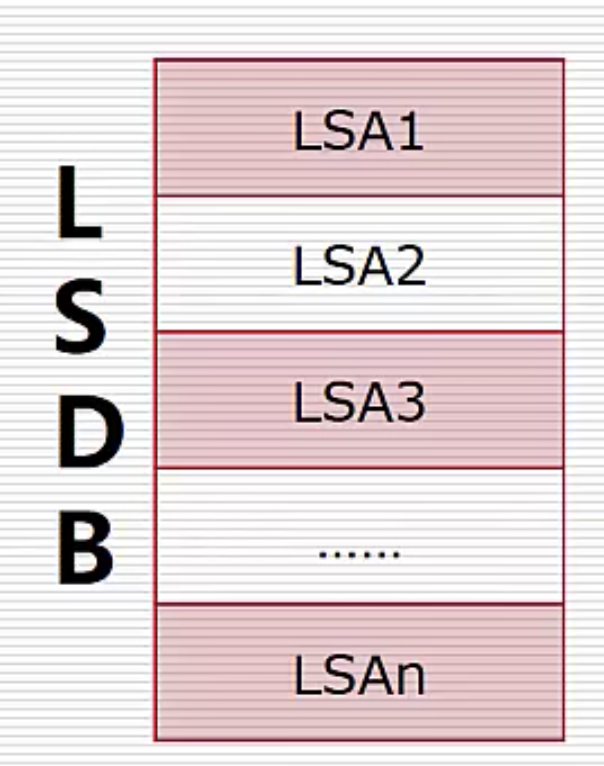
- 每个节点都有一个 LSDB(链路状态数据库),里面的每一条是一个 LSA(链路状态公告)
- 每条 LSA 描述了网络中的一个路由器的编号、直连网段、cost 等信息
更新机制
- 触发更新或者每隔 30 分钟更新一次
- 触发更新:网络发生变化时,则无需等到 30 分钟周期,立即向邻接节点发送信息
- 增量更新,只发送邻居需要的 LSA
- 收敛后,网段内的所有路由器都有相同的 LSDB
路由信息交换过程
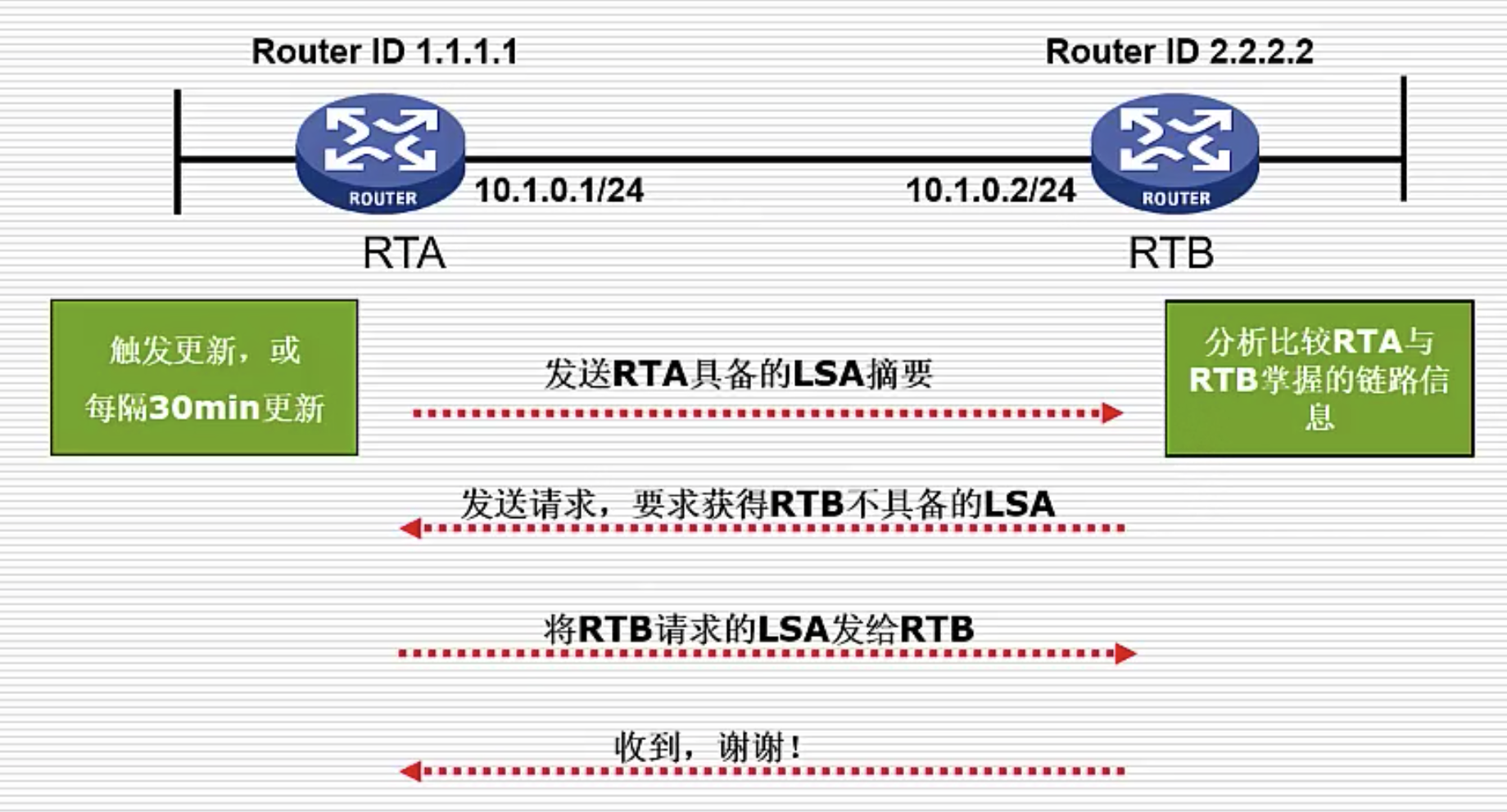
下面是 RTA 触发更新后,向 RTB 交换路由信息的过程
- 发送 RTA 所有 LSA 的摘要信息
- RTB 比较收到的 LSA 摘要与自己本地的 LSA,发送请求,希望获得自己没有的 LSA 的详细信息
- RTA 将要求的 LSA 发送给 RTB
- RTB 向 RTA 回复收到
4. 路由计算
每台路由器根据 LSDB 算出每台路由器到自己的最短路径
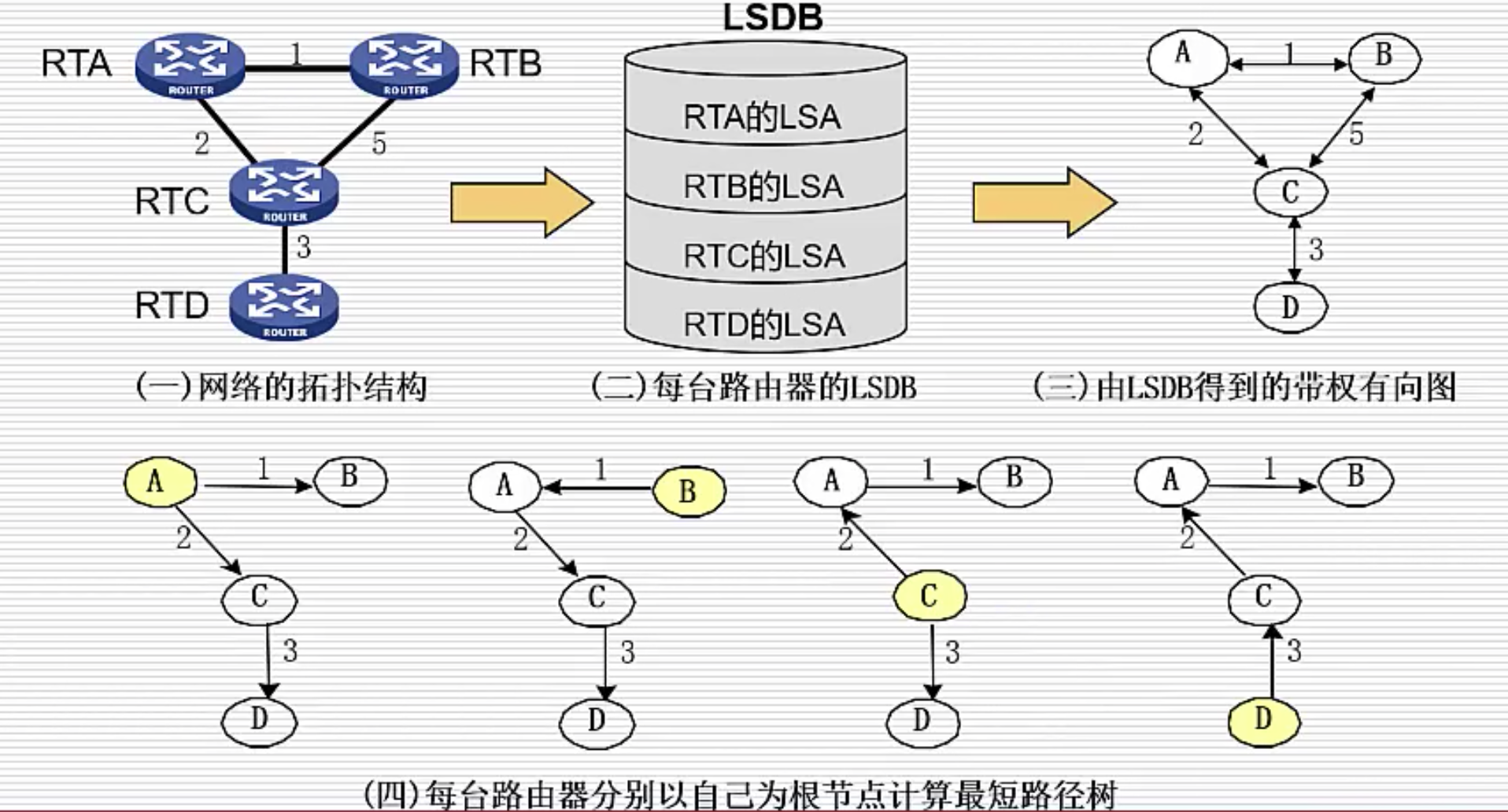
OSPF 分区域管理
LSDB 记录网络所有路由器的 LSA,所以当网络规模变大时,会导致每台路由器上都要消耗大量资源储存 LSDB,且 LSDB 信息收敛也会变得很慢,因此需要分区域管理。
- 每个区域内部的路由器的 LSDB 只需知道区域内的路由器的 LSA
- 不同区域之间通过 ASR(区域边界路由器)相连,同时有两边的 LSDB
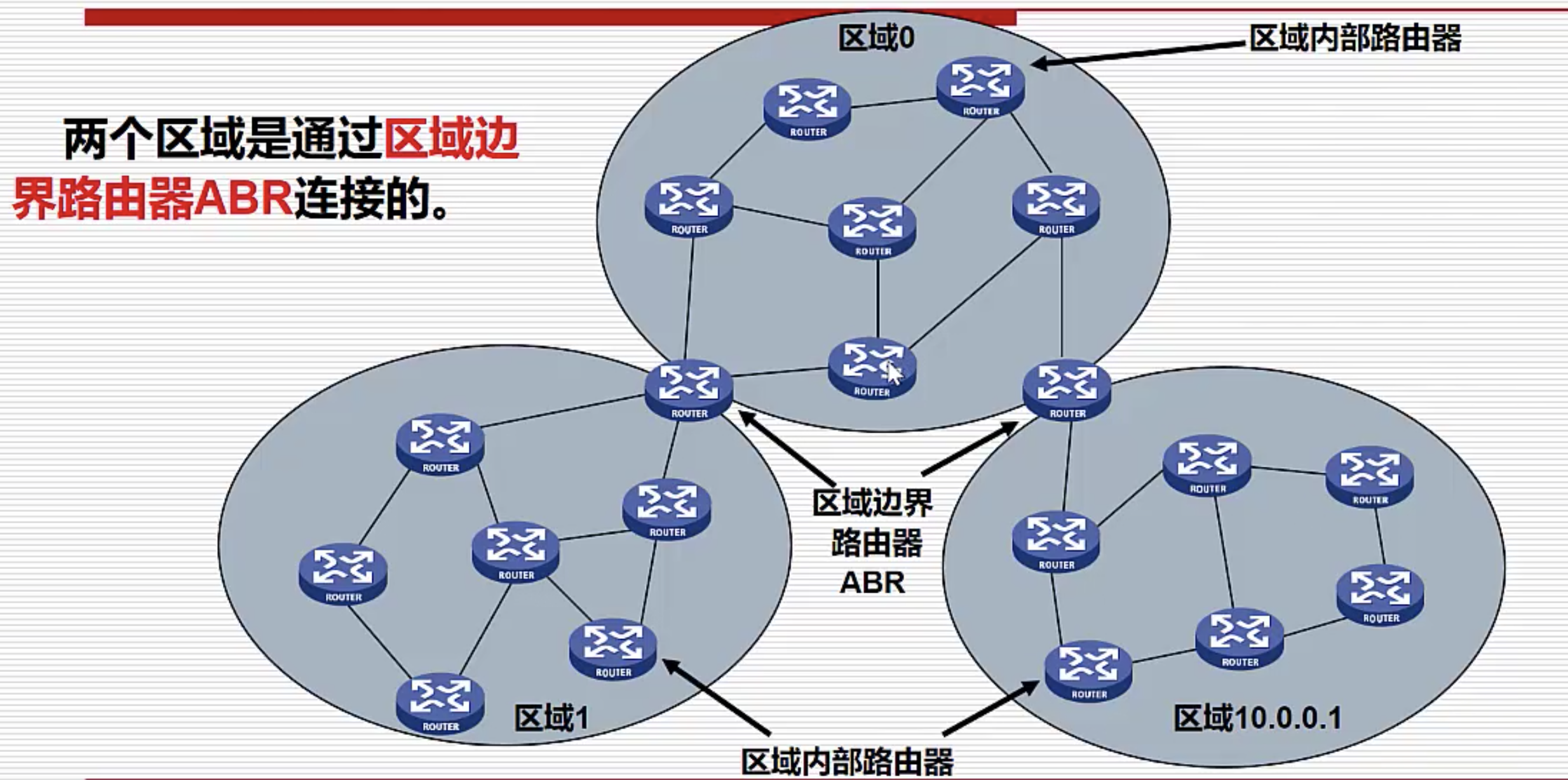
非骨干区域之间不能直接通信,需要通过骨干区域(区域 0)进行转发。
如上图中有三个区域:区域 0、区域 1、区域 10.0.0.1,其中区域 1、区域 10.0.0.1 这样的非骨干区域不能直接通信,需要先发送给区域 0,再由区域 0 转发。
Hello 包
Hello 包组成
- 功能:Hello 包用于发现邻居路由器,交换 OSPF 配置信息,并确认邻接状态。
- 内容:包括 Route ID、Priority、Hello 间隔、Dead 间隔等
1 | root@ubuntu:/etc/frr# tcpdump -i vip0 proto ospf -vvv |
组播地址 ospf-all.mcast.net
OSPF 以组播地址的方式发送 Hello 包,将 Hello 包发往组播地址 ospf-all.mcast.net(224.0.0.5),所有 OSPF 路由器都会监听该地址,如此即可确保域内所有 OSPF 路由器都收到。
Hello 包发送过程
- 定时发送:每个 OSPF 路由器按照配置的 Hello 间隔定期发送 Hello 包
- 包的构造:路由器构造 Hello 包,将其发送到多播地址
224.0.0.5 - 邻居发现:接收到 Hello 包的其他 OSPF 路由器会解析包中的信息,加入邻居表中
- 邻接关系维护:通过定期发送 Hello 包,OSPF 路由器可以维护与邻居的关系。如果在规定的 Dead 间隔内未收到某个邻居的 Hello 包,路由器将认为该邻居失效
DR 竞选
广播型网络中需选出该广播域的 DR(指定路由) 和 BDR(备份指定路由,负责在 DR 失效时接管其功能)
DR 竞选规则
- Priority 大者优先:优先选择 Priority 较大的路由为 DR,如果 Priority 设置为 0,则不参与 DR 竞选
- Route ID 大者优先:如果有多个 Priority 最大且相同的路由器,则选择其中 Route ID 最大的(Route ID 为路由器的唯一标识,通常是 IP,不可能相同)
示例:下面三个路由器中,A 的 Priority 最大,为 DR;B、C 的 Priority 相同,但 B 的 Route ID 大于 C,所以 B 为 BDR
- A 的优先级为 2,Router ID 为 1.1.1.1(DR)
- B 的优先级为 1,Router ID 为 2.2.2.2(BDR)
- C 的优先级为 1,Router ID 为 3.3.3.3
DR 竞选过程
- Hello 消息:所有路由器定期组播 Hello 消息,其中包含本路由的 Priority、Route ID 等信息
- 优先级比较:根据竞选规则比较各个路由器,优先级最高的为 DR,次高的为 BDR
- 选举后,DR 和 BDR 会向所有的路由器广播 LSA,其他所有路由器将与 DR 和 BDR 建立邻接关系
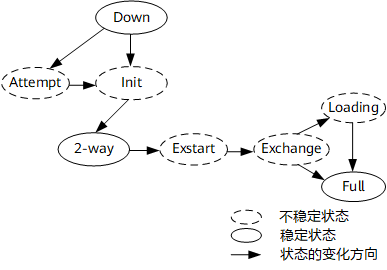
邻居状态机
RIP 和 OSPF 比较
| RIP(距离矢量路由协议) | OSPF(链路状态路由协议) | |
|---|---|---|
| 最优路径选择 | 跳数 | 链路开销 |
| 更新触发 | 每 30s | 触发更新或每隔30分钟 |
| 发送对象 | 广播到所有邻居 | 发到邻接路由器 |
| 发送信息 | 全量 RIP 路由表 | 链路状态信息摘要 |