Go 并发编程
并发基本概念
进程 Process 与线程 Thread
- 进程是系统进行资源分配和调度的一个基本单位,程序在操作系统中的一次执行过程
- 线程是进程的执行单位,是CPU调度和分派的基本单位
- 一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发执行
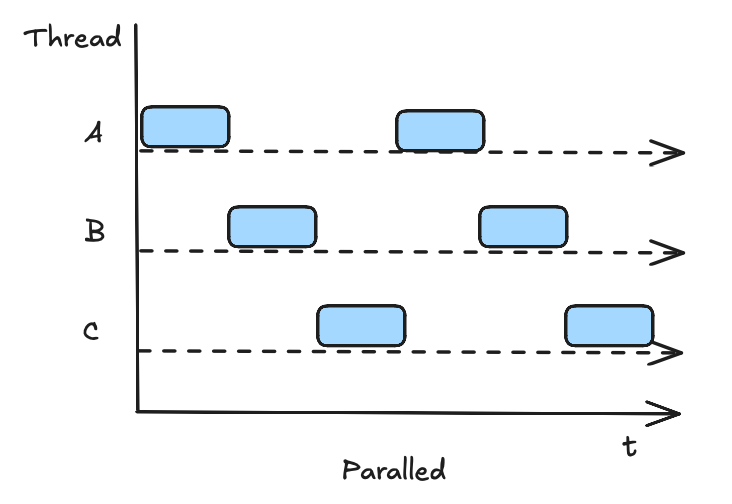
并行 Concurrent 与并发 Paralled
并行:多个线程同时操作多个资源类
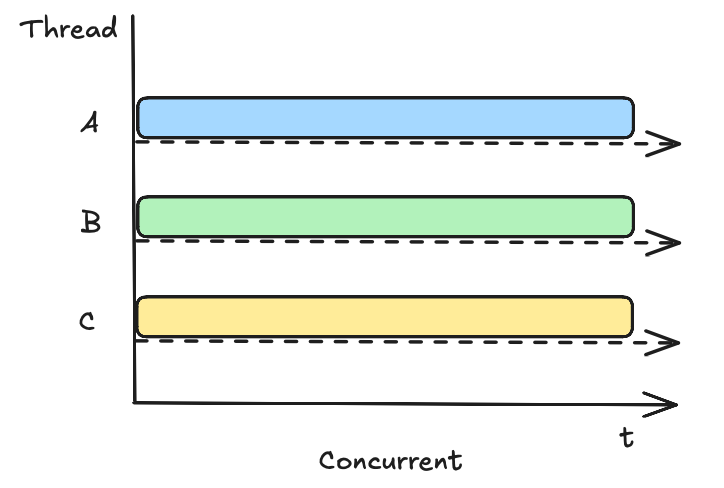
并发:多个线程交替操作同一资源类
进程 process 与线程 thread 与协程 coroutine
- 一个进程上可以跑多个线程,一个线程上可以跑多个协程
- 多个线程可以利用多个 CPU 并行,但一个线程内的多个协程是串行的,同一时刻只能有一个在运行,无法利用 CPU 多核,但不同线程内的协程之间可以并行
| 进程 process | 线程 thread | 协程 coroutine | |
|---|---|---|---|
| 切换者 | 操作系统 | 操作系统 | 用户 |
| 切换内容 | 页全局目录、内核栈、硬件上下文 | 内核栈、硬件上下文 | 硬件上下文 |
| 切换内容保存位置 | 内存 | 内核栈 | 用户栈或堆(变量) |
| 状态切换 | 用户态 —> 内核态 —> 用户态 | 用户态 —> 内核态 —> 用户态 | 用户态 |
| 切换效率 | 低 | 中 | 高 |
- 进程、线程的切换者是操作系统,操作系统决定切换时刻,用户无感
- 协程的切换者是用户,由用户程序决定切换时间
- 进程切换内容:页全局目录、内核栈、硬件上下文,切换的内容保存在内存中,采用 用户态 —> 内核态 —> 用户态
- 线程切换内容:内核栈、硬件上下文,切换的内容保存在内核栈中,采用 用户态 —> 内核态 —> 用户态
- 协程切换内容:硬件上下文,切换的内容保存在用户栈或堆(变量)中,切换过程始终处于用户态
协程 Goroutine
Go 不需要自己编写进程、线程、协程,直接使用 goroutine,在语言中内置了调度和上下文切换机制,可轻松开启上万 goroutine。
goroutine 协程概念上类似于线程,Go 程序可以智能地将 goroutine 分配给不同的 CPU,由Go的运行时(runtime)调度和管理的。
使用 goroutine
goroutine 使用时将任务包装成函数,通过 go 关键字开启
1 | go func() |
如果 goroutine 没有执行完,但主线程已经结束,goroutine 也会跟着结束。
示例
每两秒输出一次 go routine,每秒输出一次 hello,输出 10 次 hello 后结束
1 | package main |
协程调度
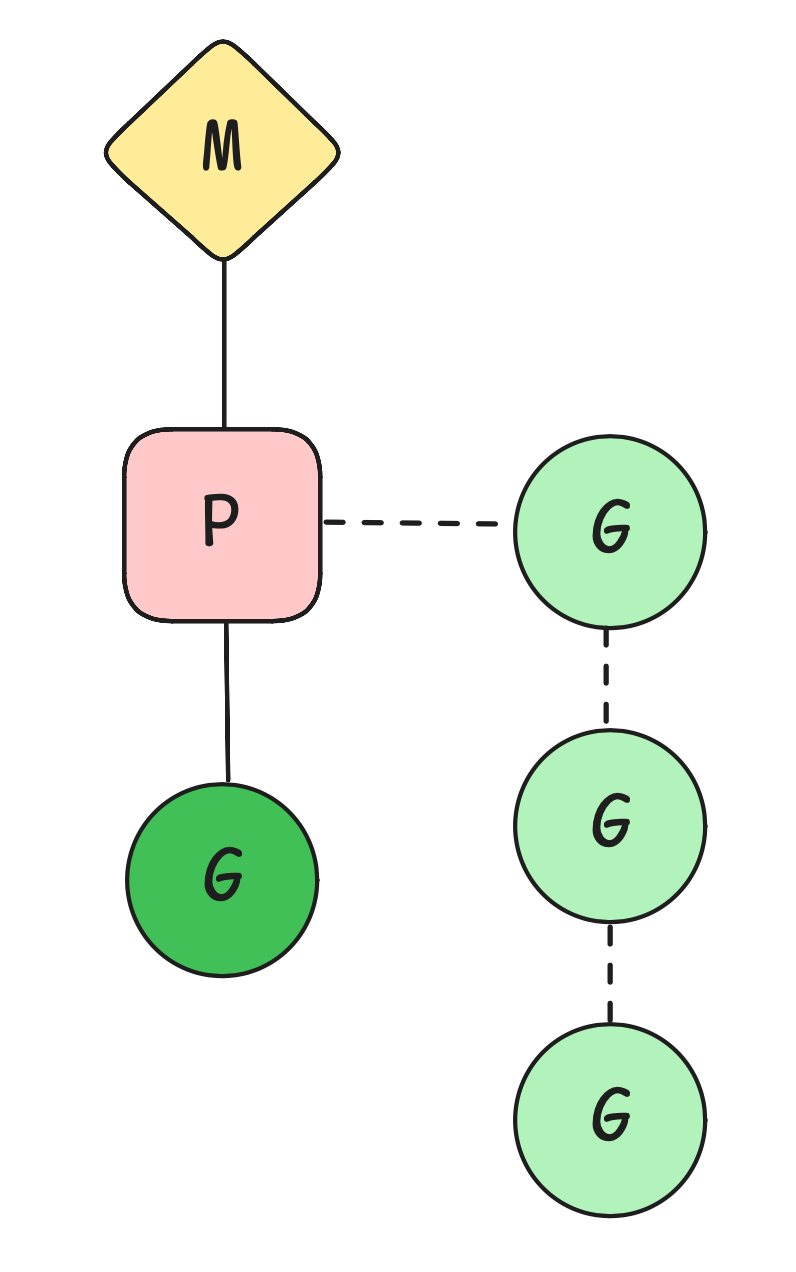
GPM 模型
goroutine 调度系统为 GPM 运行时(runtime)调度器,包括了 3 个部分—— goroutine G、处理器 P、线程 M
- G:goroutine
- 存放本 goroutine 的一些信息,以及与 P 绑定等信息
- P:Processor,处理器
- P 对 goroutine 队列进行调度
- goroutine 与线程的中间层,管理着一组 goroutine 队列,储存所管 goroutine 运行的上下文
- P 的数量决定了最大可并行数量,个数由
runtime.GOMAXPROCS设置,最大 256,默认为 CPU 数
- M:Machine,线程
- Go 运行时对操作内核线程的虚拟,与内核线程一一对应
P 管理着一群 G,调度在 M 上运行。一般比例为 G : P : M = n : 1 : 1
调度机制:
- 把占用 CPU 时间过长的 goroutine 暂停,去运行后续的 goroutine
- 当自己队列的消费光了,则去取全局队列中的 goroutine
- 如全局队列也消费光了,则去抢其他 P 的 goroutine
- 如果一个 G 长时间占据着 M,runtime 就会新建一个 M,管理阻塞 G 的 P 会将其他的 G 都挂到新建的 M 上。当旧的 M 上的 G 运行完或者被判定为死掉时,就会回收旧有的 M。
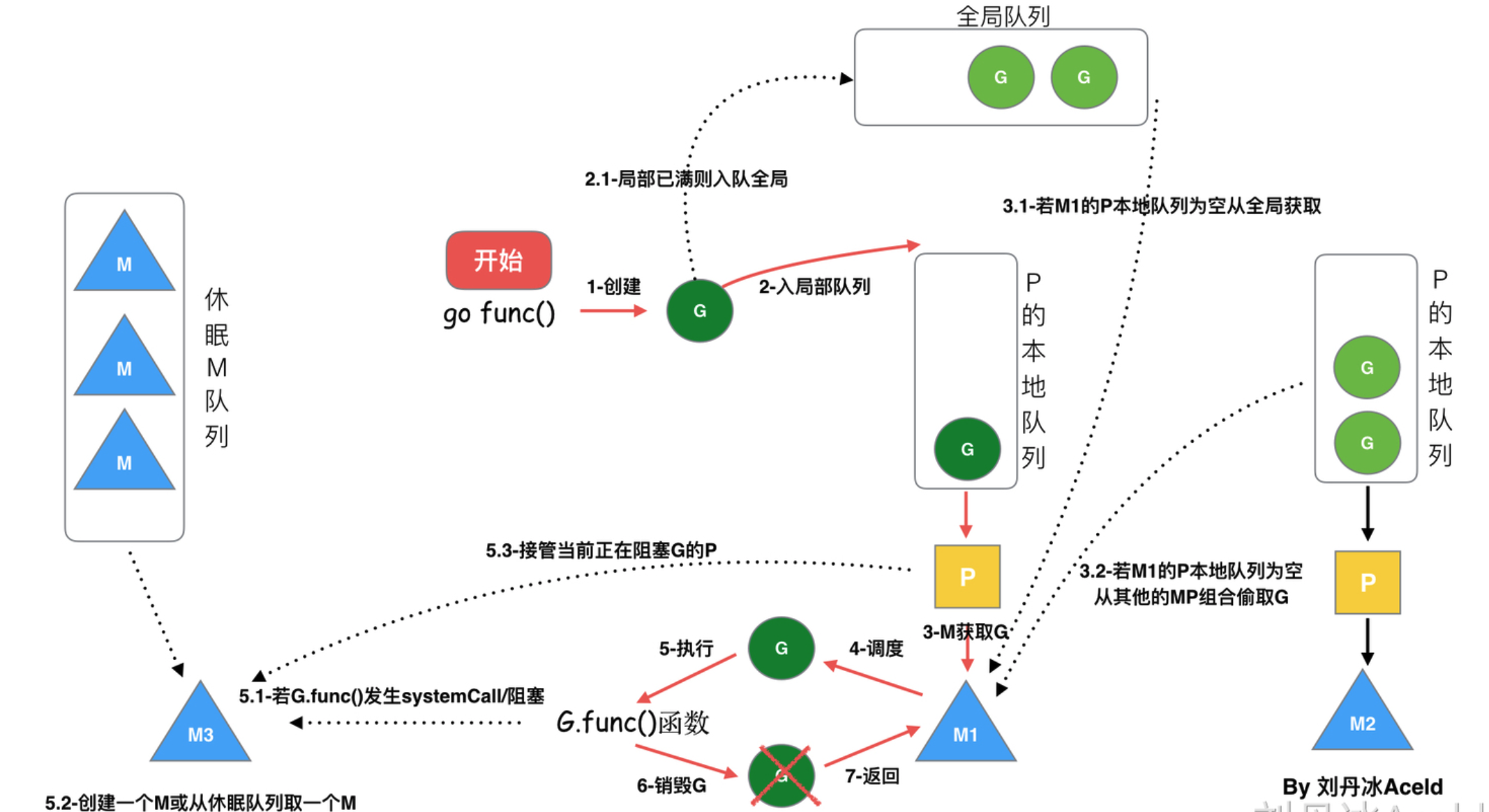
由此可以看出,从调度角度看,goroutine 相较于线程的优势:
- goroutine 的调度由 runtime 调度器调度,全程在用户态
- 线程需要内核进行调度,需要内核态和用户态之间频繁切换
runtime 包
runtime 运行时用来调度和管理 goroutine,可通过 runtime 包程序控制 goroutine 以及获取环境信息。
runtime.Gosched()
释放当前 goroutine 的 CPU 时间片给其他 goroutine 执行,当前 goroutine 等待未来的时间片再执行。
示例
下面代码,运行后有两种可能:
- 一段数字 + 两个 hello
- CPU 时间片先给数字协程,再分配给 hello 主协程
- 两个 hello
- CPU 时间片先给 hello 主协程,主协程结束后程序直接结束,不输出数字,再分配数字协程
1 | package main |
这时在主协程运行输出 hello 前,添加 runtime.Gosched(),会切到其他 goroutine 输出多次数字,等数字协程的时间片用完时,切回主协程输出 hello ,再切回数字协程输出数字,最后主协程输出 hello 后结束程序。
即输出:一段数字 + hello + 一段数字 + hello
1 | package main |
runtime.Goexit()
退出当前 goroutine,不过退出前还是会正常执行 defer 语句。
示例
下面代码,主协程休眠一秒,数字协程输出一段数字之后,主协程苏醒输出 hello
1 | package main |
添加 runtime.Goexit() 后,直接结束协程,不会输出数字,只输出 hello
1 | package main |
runtime.GOMAXPROCS()
设置可同时使用最大 CPU 核数,并返回之前的设置。
1 | func runtime.GOMAXPROCS(n int) int |
其他运行时信息
获取 CPU 核数量
1
runtime.NumCPU()
获取 GOROOT 路径
1
runtime.GOROOT()
获取操作系统
1
runtime.GOOS
数据共享
临界资源
临界资源:并发环境中多个进程/线程/协程共享的资源。
多个 goroutine 访问同一资源时,多个写 goroutine,会造成临界资源安全问题。
下面示例中,4 个售票员并发卖 10 张票,原本是希望卖到无票时所有售票员停止卖票,但同时读写就可能导致资源安全问题。
1 | package main |
如这次跑的结果,最后三个售票员检查时还有余票,但卖时已经无票了,导致票成负数。
1 | Saler 3 sales one ticket, left 9 tickets. |
互斥锁
互斥锁 sync.Mutex
多个 goroutine 同时操作同一个资源(临界区)会导致竞态问题,需要通过对资源上锁,确保同一时刻只有一个 goroutine 访问该共享资源。
声明一个互斥锁
1
var mutex sync.Mutex
在使用资源前加锁,防止其他 goroutine 同时使用该资源
1
mutex.Lock()
在使用完资源后解锁,释放该资源给其他 goroutine 使用
1
mutex.Unlock()
上面的用例,在查看票数前加锁,再售票和退出前解锁,如此就不会出现多卖出票的情况。
1 | package main |
读写互斥锁 sync.RWMutex
互斥锁是完全互斥的,无关是读还是写。但其实并发读并不会出现资源竞争的问题,所以引入读写锁,不限制并发读,但限制并发读写、写写。
| 读 | 写 | |
|---|---|---|
| 读 | Y | N |
| 写 | N | N |
声明一个读写互斥锁
1
var mutex sync.RWMutex
在写资源前加写锁,
1
mutex.Lock()
在写完资源后解写锁,
1
mutex.Unlock()
在读资源前加读锁
1
mutex.RLock()
在读完资源后解读锁
1
mutex.RUnlock()
示例
1 | package main |
原子操作 atomic
原子操作即不能被中断的操作,对资源进行原子操作时,CPU 不会再对该资源进行其他操作。原子操作无锁,通过 CPU 指令直接实现。
通过互斥锁操作会涉及内核态的上下文切换,Go 可以调用 atomic 包在用户态完成原子操作来保证并发安全。
- 原子操作支持的类型:
int32、int64、uint32、uint64、uintptr、unsafe.Pointer,即整数和指针
以 int64 为例,取变量地址用于操作
读取
1
func atomic.LoadInt64(addr *int64) (val int64)
写入
1
func atomic.StoreInt64(addr *int64, val int64)
修改
1
func atomic.AddInt64(addr *int64, delta int64) (new int64)
交换
1
func atomic.SwapInt64(addr *int64, new int64) (old int64)
比较交换,交换前先检查当前值是否是 old,如是则交换成 new,如不是则不交换
1
func atomic.CompareAndSwapInt64(addr *int64, old int64, new int64) (swapped bool)
管道 Channel
Go 的并发模型是 CSP,Communicating Sequential Process,提倡使用通信共享内存,而不是通过共享内存方式进行通信。
Go 可以通过共享内存来实现数据共享,使用锁来防止竞态,但这不可避免的加大了性能问题。由此引入了管道 Channel 的概念,用于 goroutine 之间通信。
创建 Channel
Channel 是引用类型,每个 Channel 都需要定义其允许传输的数据类型。
1 | var ch chan 数据类型 //零值为nil |
通道的零值为 nil,因此需要使用 make 来定义(缓冲区大小可缺省)
1 | ch := make(chan 数据类型 [, 缓冲区大小]) |
Channel 操作
在定义了 Channel 后,可对其进行下面操作,以 int 类型为例
1 | ch := make(chan int) |
发送
1
ch <- 10
- 当存在等待的接收者时,直接将数据发送给阻塞的接收者
- 当不存在等待的接收者,但缓冲区存在空余空间时,将数据写入缓冲区
- 当不存在等待的接收者,且不存在缓冲区或者缓冲区已满时,阻塞等待其他 goroutine 从 Channel 中接收数据
接收
1
2
3<-ch //丢弃通道值
data := <-ch //接收通道值到data
data, ok := <-ch //接收通道值到data,ok接收通道是否关闭(false,则通道已关闭)- 当存在等待的发送者时,从阻塞的发送者或者缓冲区中获取数据
- 当不存在等待的发送者,但缓冲区存在数据时,从缓冲区接收数据
- 当不存在等待的发送者,且不存在缓冲区或者缓冲区不存在数据时,阻塞等待其他 goroutine 向 Channel 中发送数据
关闭,如果不再需要往通道发送值,则可以关闭通道,关闭通道不是必须的,可以自动通过垃圾回收机制回收
1
close(ch)
关闭后的通道:
- 对关闭后的通道发送值会导致 panic
- 对关闭后的通道接收会一直获取到值,知道通道空
- 对关闭后且已经空的通道接收会得到对应数据类型的零值
- 关闭已经关闭的通道会导致 panic
| Channel缓冲区 | nil | 非空 | 空 | 满 | 非空非满 |
|---|---|---|---|---|---|
| 发送 | 阻塞 | 发送值 | 发送值 | 阻塞 | 发送值 |
| 接收 | 阻塞 | 接收值 | 阻塞 | 接收值 | 接收值 |
| 关闭 | panic | 关闭成功,读取所有数据后,返回零值 | 关闭成功,返回零值 | 关闭成功,读取所有数据后,返回零值 | 关闭成功,读取所有数据后,返回零值 |
无缓冲的通道
无缓冲通道,又称阻塞通道、同步通道,定义 Channel 时不设置缓冲区大小即为无缓冲通道。
此类 Channel 发送和接收都无缓冲,所以无接收时发送会被阻塞,直到其他 goroutine 从该通道读取数据;同理,无发送时接收会被阻塞,直到其他 goroutine 发送到该通道。
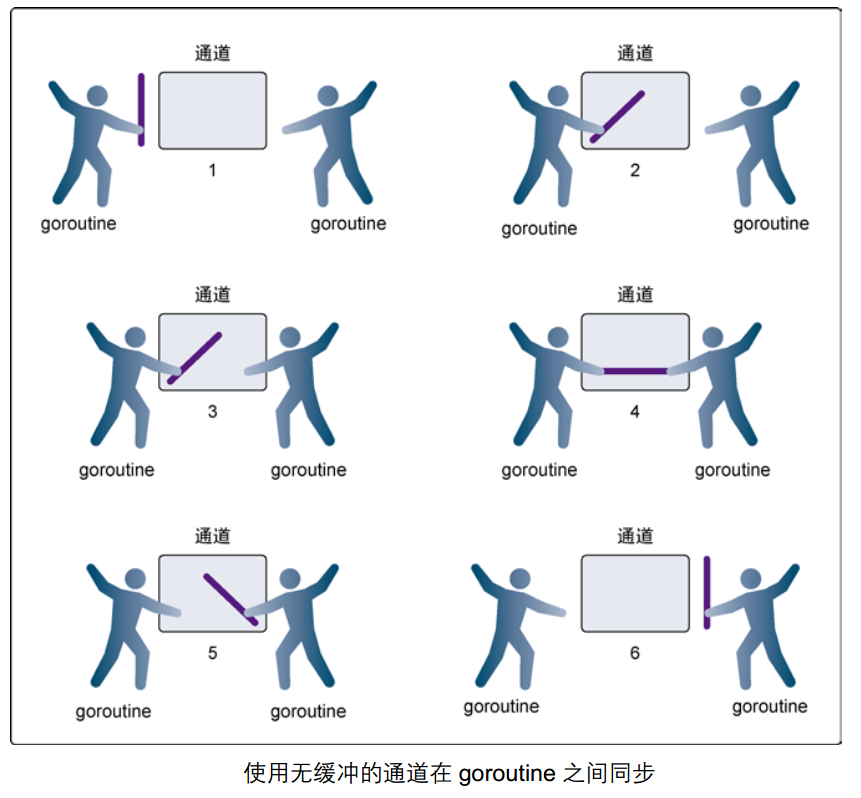
下面错误用例,发送数据到 Channel,无接收,阻塞,无法运行到接收步骤,于是发生死锁报错
1 | fatal error: all goroutines are asleep - deadlock! |
1 | package main |
需要启动另一个 goroutine 接收,解开死锁
1 | package main |
有缓冲的通道
定义 Channel 时设置缓冲区大小即可设置为有缓冲通道,在缓冲区有剩余时,即使无接收者,也不阻塞发送。
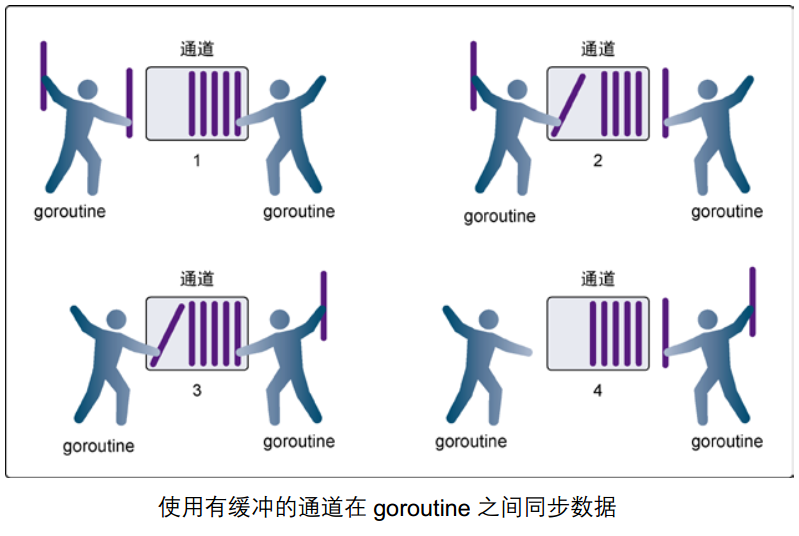
上述死锁用例,加上缓冲区,即可正常运行。
1 | package main |
单向通道
有些 goroutine 函数调用 Channel 仅需发送或者接收,则可以使用单向通道进行限制。
只能发送的通道
1
chan<- int
只能接收的通道
1
<-chan int
下面例子,两个函数一个仅需要发送,一个仅需要接收,即可传入单向通道
1 | package main |
通道的遍历
循环从通道取值的方法
方法一:使用 for 持续循环
1 | package main |
方法二:for...range,既可以循环取值,并且在通道关闭后退出
1 | package main |
通道的调度
通过 select 随机运行一个接收到的 Channel 的 case
- 如果有可接收的 Channel,则随机运行其中一个 case
- 如果没有可接收的 Channel,则运行
defaultcase - 如果没有可接收的 Channel,且没有
defaultcase,则会阻塞直到有接收到 Channel
使用无限 for 循环包裹 select,则可实现持续监听多个通道,触发相应操作。
1 | for { |
sync 包
sync.WaitGroup
在多线程并发过程中,如果主协程结束,其他 goroutine 也会跟着结束,所以经常需要让主协程等待其他 goroutine 结束。使用 time.Sleep 过于生硬,不合适。于是引入了 sync.WaitGroup 处理该问题 。
(wg * WaitGroup) Add(delta int):计数器 + delta(wg *WaitGroup) Done():计数器 -1(wg *WaitGroup) Wait():阻塞直到计数器变为 0
每开一个并发 goroutine 就让计数器 +1,并发 goroutine 结束时则让计数器 -1,主协程调用 Wait() 阻塞直到所有 goroutine 结束,计数器清零。
1 | package main |
sync.Once
sync.Once 提供函数只执行一次的方法,如初始化配置、数据库连接此类并发只需要调用一次的函数,可用此方法
1 | func (o *Once) Do(f func()) |
下面示例,funcA 和 funcB 都需要调用 InitConfig 函数,使用 sync.Once,可使得该函数只被调用一次。
1 | package main |
输出
1 | Init Configuration |
sync.Map
Go 原生的 map 并不是并发安全的,需要额外加锁。sync 包提供 sync.Map 则是一种并发安全的 map,无需加锁。内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
1 | package main |
定时器
周期性定时器 ticker
ticker 是周期性定时器,除非主动停止,就会一直循环计时下去。如果希望每隔一段时间执行一次,推荐使用 ticker
| 用法 | 作用 |
|---|---|
func time.NewTicker(d time.Duration) *time.Ticker |
定义一个定时器 ticker,每隔一个间隔时间就会向 .C 通道发送当前时间 |
func (t *time.Ticker) Stop() |
回收资源,否则会产生内存泄漏 |
<-t.C |
每隔一个设置的时间就会从通道接收到当前时间 |
以下示例,每隔 5s 输出当前时间
1 | package main |
一次性定时器 timer
timer 是一次性定时器,只计时一次,重新开始计时需要重置。如果希望只执行一次,或者需要重新设置间隔时间的,推荐使用 timer
| 用法 | 作用 |
|---|---|
func time.NewTimer(d time.Duration) *time.Timer |
定义一个定时器 timer,过一个间隔时间后会向 .C 通道发送当前时间 |
<-t.C |
过一个设置的时间从通道接收到当前时间 |
func (t *time.Timer) Stop() bool |
停止当前计时,如果当前在计时,则返回 true,并不会再发送到通道;如果不在计时中,则返回 fasle |
func (t *time.Timer) Reset(d time.Duration) bool |
重置计时器,如果现在正在计时,则停止当前计时,重新计时(返回同 Stop) |
以下示例,使用一次性计时器 timer 模拟周期性计时器 ticker
1 | package main |