DPDK 学习
DPDK 概述
包处理
基于系统是网络终端还是中间件,包处理会有不同的范围。一般来说,包含了包的接收和传输、包头的解析、包的修改以及转发,这些步骤发生在多个协义层。
- 对于网络终端,包会发给本地应用进行更多的处理,如包的加解密、隧道覆盖,这些都可能是包处理、会话建立及结束的一部分。
- 对于中间件,包会被转发给网络中的下一跳。一般这种系统需要处理大量的进出数据包,功能包括包查询、访问控制、QoS 等等。
传统包处理
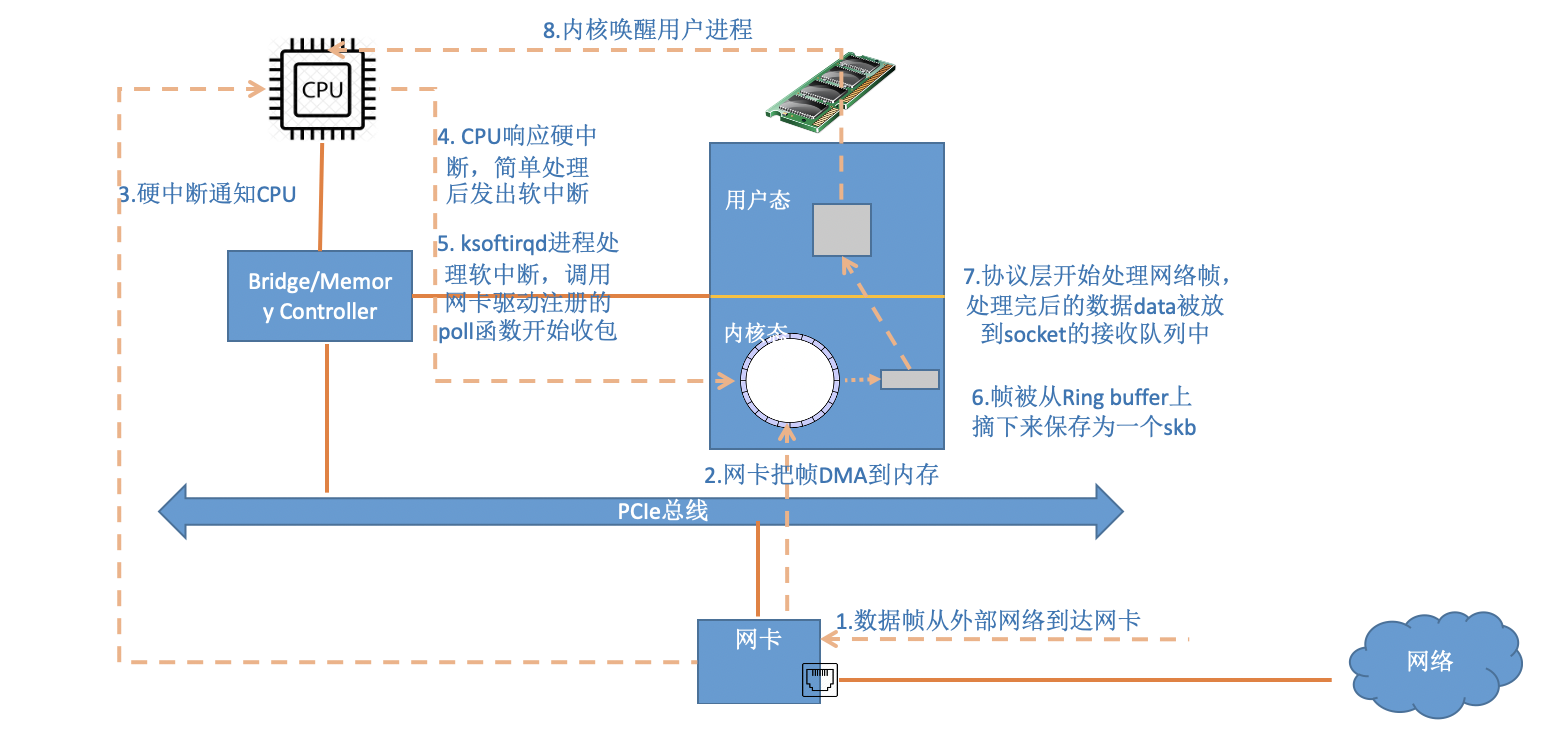
在 DPDK 前,Linux 一般的网卡包处理过程如下:
- 包的数据帧抵达网卡
- 网卡把包的帧以 DMA(Direct Memory Access)的方式写到内存
- 网卡硬中断通知 CPU 有包到达
- CPU 响应硬中断,简单处理后,发出软中断,尽量快速释放 CPU 资源
- ksoftirqd 内核线程检测到软中断后,调用网卡驱动注册的 poll 函数开始轮询收包
- 帧从 RingBuffer 摘下,收到的包交给 Linux 内核的各个协议栈处理
- 如果最终收包的应用在用户态,包中的信息会从内核态拷贝到用户态
- 如果最终收包的应用在内核态,包中的信息直接在内核态被处理
在上述包处理过程中,Linux 采用了 NAPI 和 Netmap两个机制来加快包处理过程
- NAPI 即轮询收包,一次处理多个数据包,处理结束后,再回到中断状态
- Netmap 则是数据包通过共享池的方式,减少包从内核态到用户态的复制
但这依旧不够,如何使包处理性能更强?待解决的问题如下:
- Linux 包处理过程需要在内核态和用户态之间转换,任务切换、cache 替换等都会带来不小的开销
- 随着 CPU 核数越来越多,早期为了适应 CPU 核数较少的分时调度机制限制了处理性能
由上述问题,期望的包处理框架应具有如下能力:
- 一个软件方式可以在 x86 CPU 进行包处理
- 自定义包处理
- 能使用多核架构,具有高性能
- 将一般的 Linux 系统调教为包处理环境
DPDK 特性
DPDK 就是回应上述期待的包处理技术,DPDK 拥有下面这些特性:
- 轮询
- 为网卡的收发包分配独立的核,不需要与其他任务共享核,因此该类核可以无限循环地检查是否有包到达以及是否需要发送包
- 该方法减少了中断服务导致的上下文切换等开销
- 用户态驱动
- 在大多数期间下,包最后都会被发到用户态,但 Linux 网卡驱动在内核态
- 用户态驱动可以避免包从内核态到用户态不必要的内存拷贝,并避免系统调用开销
- 用户驱动更加灵活,可自定义,不受限于内核现有的数据格式与行为定义
- CPU 亲和
- DPDK 虽然工作在用户态,但线程调度依旧依赖内核
- 线程在不同的核间切换,由于缓存未命中和缓存写回,会导致性能的下降
- 同一核内不同任务切换,每次切换都需要保存当前状态寄存器到堆栈中,并恢复切换后的进程的状态信息,带来了额外的开销
- CPU 亲和,即将进程或线程绑定到一个或多个特定的 CPU,进一步可独占该核,而不会迁移到其他核
- 如此,独占固定的核运行 DPDK,既避免了核之间的切换,提高了缓存命中率,又使得该核不用频繁的进行任务切换,减少了任务切换的开销
- DPDK 虽然工作在用户态,但线程调度依旧依赖内核
- 低访存开销
- 包处理大量的 I/O 需要频繁地访存,需要降低访存带来的开销
- 如采用大页技术降低 TLB miss
- 软件调优
- 一系列调优方式,如 cache line 对齐、cache line 共享等等
DPDK 框架
下面是 DPDK 的基本模块,作为开发包处理系统的基础层,可以用软件模拟大部分的网络功能。
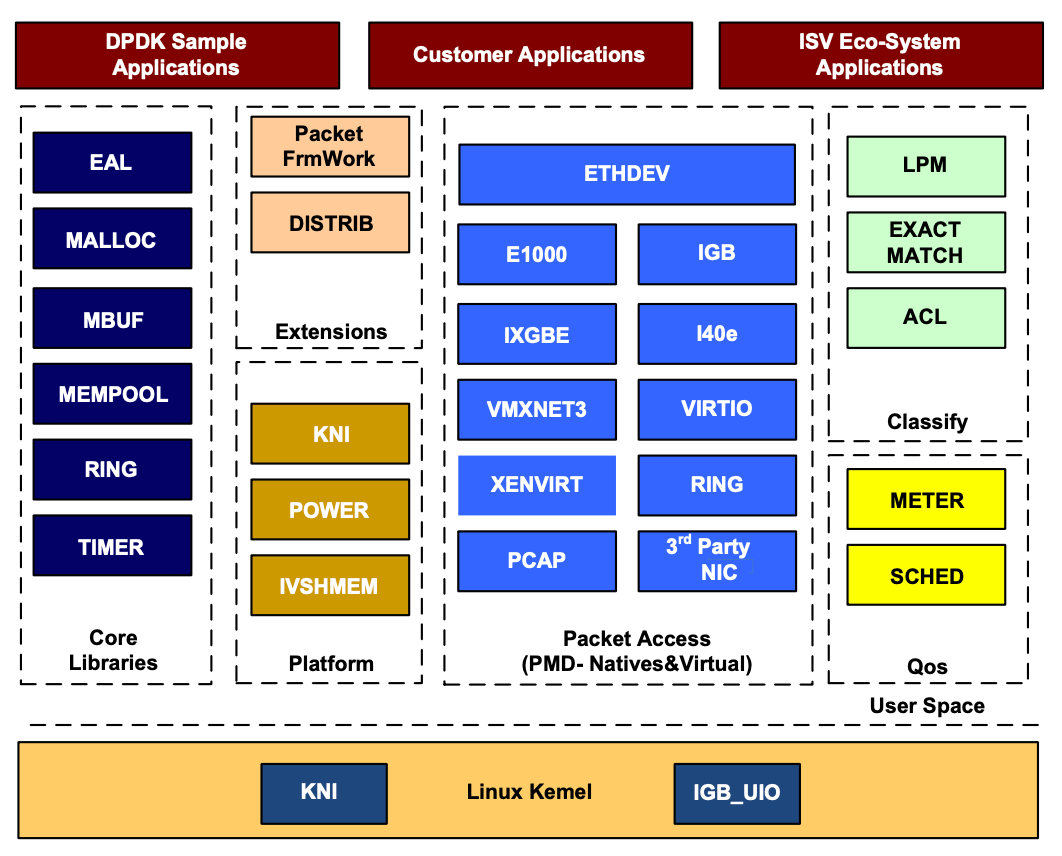
在最底部的内核态有三个模块 :KNI、IGB_UIO、VFIO,其中
- KNI,Kernel Network Interface,内核网络接口,提供 DPDK 和内核交换报文的解决方案。
- KNI 模拟了一个虚拟网卡,提供 DPDK 与 Linux 内核之间通讯,允许报文被用户态接收后转发到 Linux 内核协议栈。
- IGB_UIO,通过 UIO 技术,在初始化过程中将网卡硬件寄存器映射到用户态。
- UIO 技术是一种用户态 I/O 框架,支持将用户态驱动的很少一部分运行在内核空间,大部分则运行在用户空间
- IGB_UIO 则是 UIO 的,形态上是一种网卡驱动,网卡绑定 IGB_UIO 驱动后,相当于隔离了内核的网卡驱动,同时 IGB_UIO 还能够完成网卡中断内核态的初始化,并将中断信号映射到用户态
- VFIO,可以安全地把设备 I/O、中断、DMA 等暴露到用户空间,从而可以在用户空间完成设备驱动的架构
在上层的用户态,DPDK由很多库组成,主要包括:核心部件库(Core Libs)、平台相关模块(platform)、网卡轮询模式驱动模块(PMD-natives & virtual)、QoS 库、报文转发分类算法(classify 算法)等几大类。
- 核心部件库(Core Libs):提供环境抽象层(EAL)、大页内存、缓存池、定时器以及无锁环等基础组件
- PMD 库:提供所有用户态驱动,以便通过轮询和线程绑定得到高网络吞吐量。支持各种本地或者虚拟网卡
- Classify 库:支持精确匹配(exact match)、最长后缀匹配(LPM,longest prefix match)、通配符匹配(ACL,access control list)和 cuckoo hash 算法,这些算法用来包处理中的查表操作
- 加速器 API:支持包安全(CryptoDev)、数据压缩(CompressionDev)和用于内核间通信的事件建模器(EventDev)
- QoS 库:提供网络服务质量相关组件,如限速(Meter)和调度(Sched)
- 平台相关模块:
- POWER:能耗管理,运行时调整 CPU 时钟频率,可以根据分组接收频率动态调整 CPU 频率,或进入 CPU 的不同休眠状态
- KNI:通过 kni.ko 模块将数据报文从用户态传递到内核态协议栈,以便用户进程使用传统的 Socket 接口对相关报文进行处理
- Packet Framework 和 DISTRIB 为搭建更复杂的多核流水线处理模型提供了基础的组件
核心组件
核心组件是用来做高性能包处理 app 的一系列库。
大页技术
物理内存和虚拟内存
CPU 的内存管理包含两个概念:
- 物理内存:即安装在计算机的物理内存条
- 虚拟内存:虚拟的内存地址
多进程操作系统,进程不能直接访问物理内存,避免不安全行为,每个进程都维护了一套自己的虚拟地址,由 CPU 的内存管理单元(MMU)将虚拟地址转换到物理地址,再通过物理地址访问实际的物理内存,保证各个进程之间内存不互相干涉。

转换过程对进程是全透明的,进程可认为程序直接通过虚拟地址访问虚拟内存得到了数据,实际是通过虚拟地址映射到的物理地址在物理内存得到的数据。
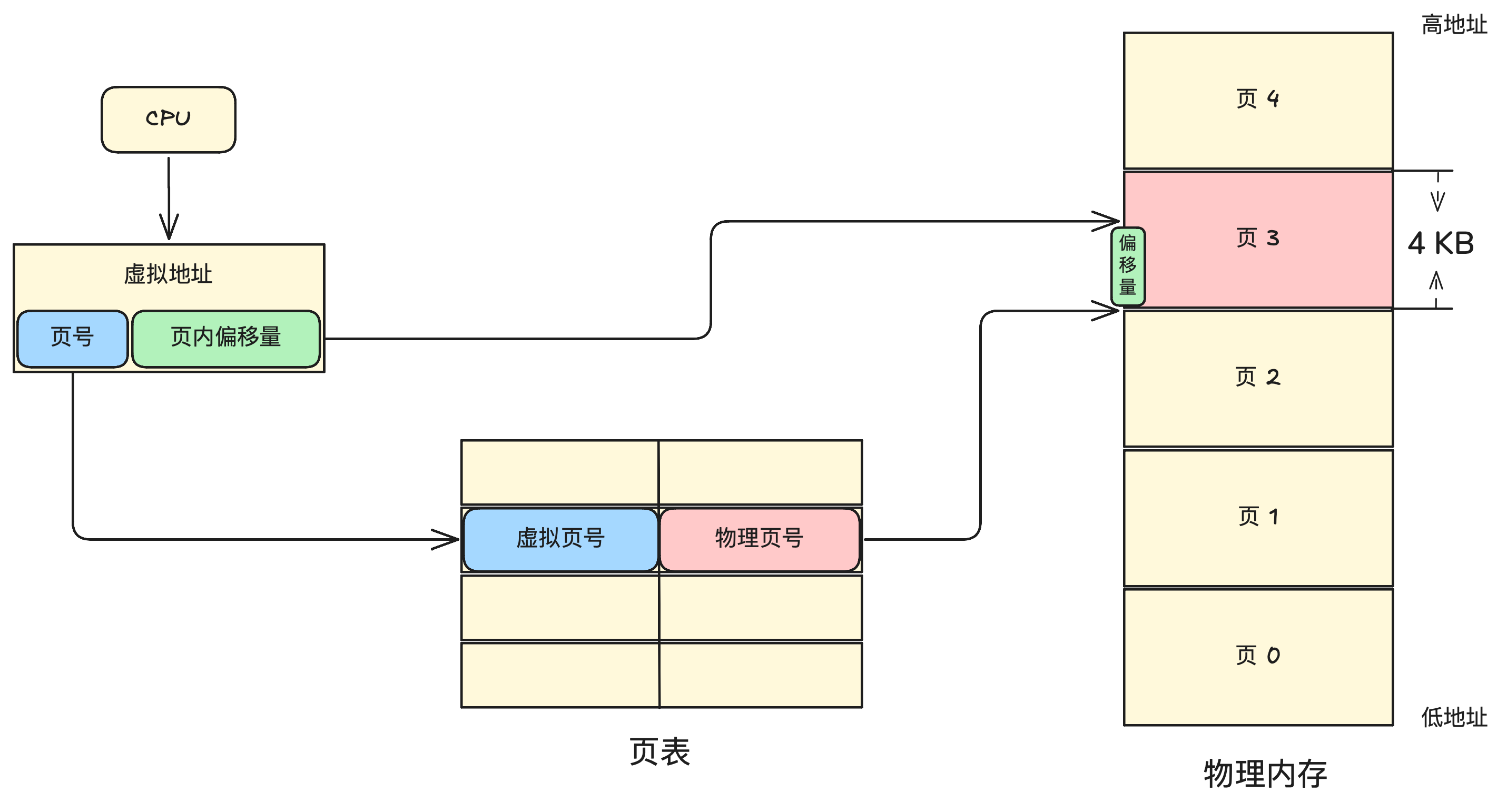
内存分页
分页是整个虚拟和物理内存空间切成一段段固定尺寸的大小的页(Page),在 Linux 的缺省配置,页大小为 4 KB。
分页机制下,虚拟地址分为了页号和页内偏移量两个部分
- 根据虚拟页号,在页表中找到对应的物理页号
- 在物理页号对应的物理内存页上,加上页内偏移量,得到物理内存地址
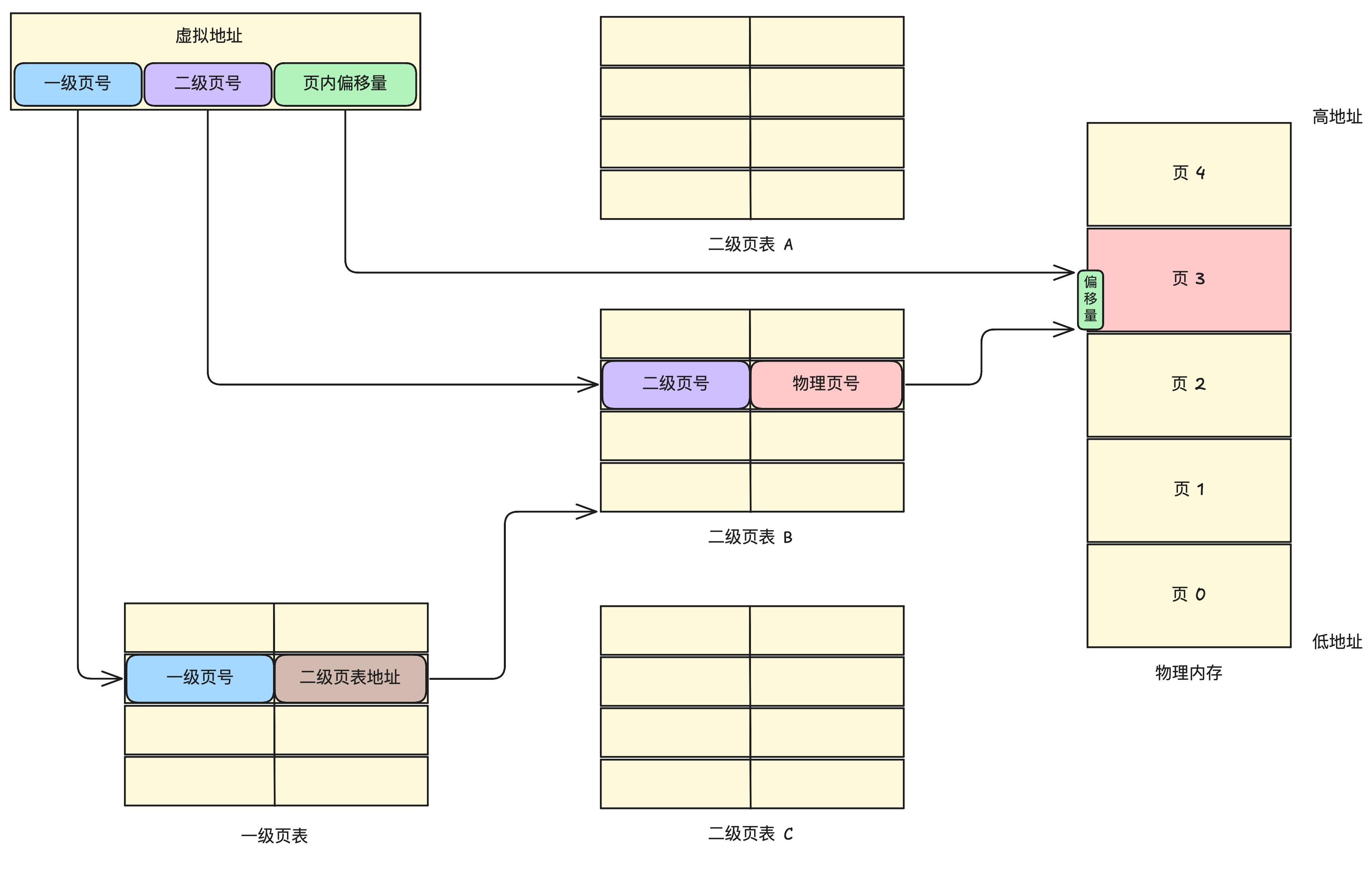
多级页表
但分页方式依旧有缺陷,假如每个进程的虚拟内存有 4GB,采用默认的页大小 4KB,也就是需要对应 1M 个物理页,即需要 1M 个页表项,每个页表项 4B,那么每个进程都需要 4MB 的大小空间用于存储页表。100 个进程就会需要 400 MB 空间。
由此引出多级页表,将虚拟页号和物理页号的对应拆成多级,对于相同的物理页数量,映射使用的页表总大小减小。
以二级页表为例,虚拟地址分为了一级页号、二级页号和页内偏移量三个部分
- 在一级页表,根据一级页号找到对应的二级页表地址
- 在二级页表地址对应的二级页表上,根据二级页号找到对应的物理页号
- 在物理页号对应的物理内存页上,加上页内偏移量,得到物理内存地址
TLB
多级页表虽然解决了空间问题,但是多了几道地址转换的查表,时间成本增加。
由此引入 TLB(Translation Lookaside Buffer)快表,程序有局部性,对于一个程序而言,往往访问的都是内存的某些区域,所以可以将进程经常访问的页表项存入 Cache 中,这个 Cache 即是 TLB 快表。
在之前的步骤前加上查询 TLB 快表的流程,TLB 快表中存储了经常访问的虚拟页号到物理页号的映射。
- 先查询 TLB,如果查到了,则直接快速拿到物理地址
- 如果 TLB 未能查到,也就是 TLB miss,则按照正常地流程步骤获取物理地址,并将其加入 TLB 中
大页
TLB 的大小有限,即可以存储的快速查找的虚拟页号到物理页号的映射有限。
在 Linux 的缺省配置,页大小为 4 KB。但也支持更大的尺寸,如 2MB 或 1 GB 的大页,这样虽然 TLB 的页表项数量不变,但是每一项对应的物理页面的大小增加,可以由 TLB 直接命中的范围也就增加了。
TLB 命中概率增加,TLB miss 发生概率减小,如此大大增加了访存效率。
激活大页
设置大页,2MB 的大页设置 1024 个
1 | echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages |
查看大页设置
1 | root@ubuntu:~# cat /proc/meminfo |grep Hu |
内存管理
lcore
MEMPOOL Library
rte_pktmbuf_pool_create
rte_pktmbuf_pool_create_by_ops
rte_mempool_lookup
rte_mempool_free
环境抽象层 EAL
EAL(Environment Abstraction Layer,环境抽象层)用于获取底层资源。EAL 可以使用通用接口,屏蔽应用和库的环境特殊性,同时负责初始化分配资源。
EAL 主要提供下列典型服务:
- DPDK 的加载和启动:DPDK 和指定的程序链接成一个独立的进程,并以某种方式加载
- CPU 亲和性和分配处理:DPDK 提供机制将执行单元绑定到特定的核上,就像创建一个执行程序一样。
- 系统内存分配:EAL 实现了不同区域内存的分配,例如为设备接口提供了物理内存。
- PCI 地址抽象:EAL 提供了对 PCI 地址空间的访问接口。
- 跟踪调试功能:日志信息,堆栈打印、异常挂起等等。
- 公用功能:提供了标准 libc 不提供的自旋锁、原子计数器等。
- CPU 特征辨识:用于决定 CPU 运行时的一些特殊功能,决定当前 CPU 支持的特性,以便编译对应的二进制文件。
- 中断处理:提供接口用于向中断注册/解注册回掉函数。
- 告警功能:提供接口用于设置/取消指定时间环境下运行的毁掉函数。
EAL 参数
内核初始化与启动
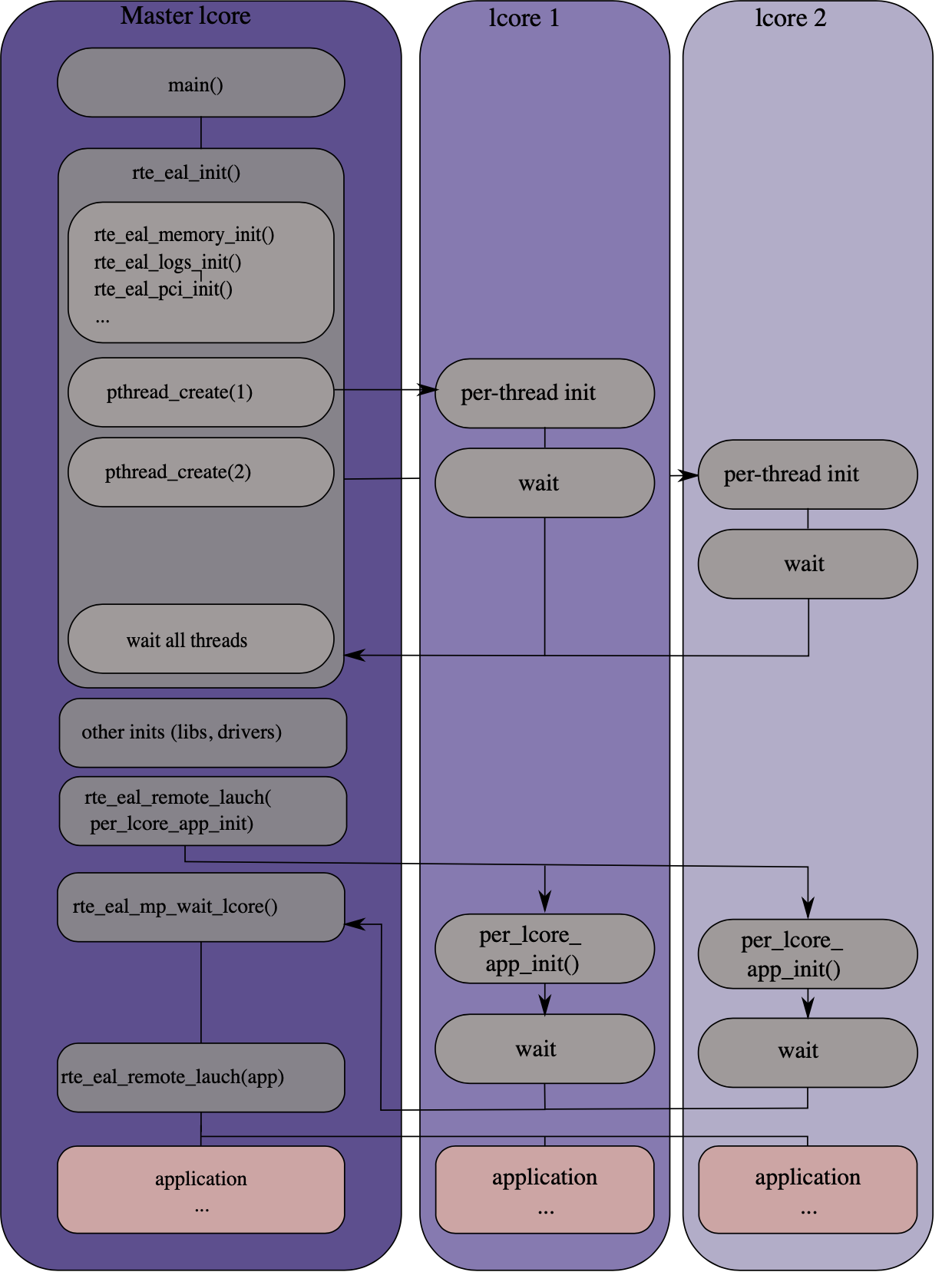
内核的初始化由 rte_eal_init() 函数完成,待所有核完成初始化后,通过 `rte_eal_remote_launch() ` 函数启动各个核上的应用,具体过程如下
- MAIN lcore 启动
main()函数 MAIN lcore 调用
rte_eal_init()进行各种初始化- 命令行参数
-l可以设置运行 lcore,第一个作为 MAIN lcore,剩下的作为 WORKER lcores,如不设置, - 在 MAIN lcore 中主要包括内存、日志、PCI 等初始化工作
- 在 WORKER lcores 启动线程,并使之处于 WAIT 状态
- MAIN lcore 等待所有逻辑核初始化完毕
- 命令行参数
其他初始化工作,如初始化 lib 库和驱动
MAIN lcore 调用
rte_eal_remote_launch(func, arg, worker_id)函数,给 WORKER lcore 分配 function 并启动- 发送信息到对应 worker_id 的 WORKER lcore,确认该核处在 WAIT 状态
- WORKER lcore 接收到信息,切换到 RUNNING 状态,并执行 function 带 arg 参数
- WORKER lcore 执行 function 完毕后,切换回 WAIT 状态,function 的返回值可以通过
rte_eal_wait_lcore()读取
MAIN lcore 调用
rte_cal_mp_wait_Icore()函数,等待所有 WORKER lcores 完成 app- 如果不设置等待,MAIN lcore 会直接结束,不知道其他核的运行情况
- 等待所有的核完成 function 切回 WAIT 状态
关闭与清理环境
在 MAIN lcore 程序的最后运行 rte_eal_cleanup() 函数,用于清理 EAL 环境。rte_eal_cleanup() 将会释放 rte_eal_init() 分配的内存,在清理之后,DPDK 函数就无法再被调用了。
EAL 库
rte_eal.h 中的常用函数
rte_eal_init()
用于初始化 eal 层,只能在 main() 中使用。
1 | int rte_eal_init(int argc, char **argv) |
- 输入:main 函数的参数
- 输出:返回 eal 使用了的参数的数量。如果 eal 初始化失败,则返回负数。
DPDK 环境搭建
以 Ubuntu 20.04.6 安装 DPDK 23.11 为例
依赖
安装 C 编译器
1
apt install build-essential
安装 meson 和 ninja
1
apt install meson ninja-build
安装 pyelftools
1
pip3 install python3-pyelftools
安装 NUMA Library
1
apt install libnuma-dev
大页
设置大页
1 | echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages |
DPDK 安装
下载解压
1
2
3wget http://fast.dpdk.org/rel/dpdk-23.11.tar.xz
tar xJf dpdk-23.11.tar.xz
cd dpdk-23.11设置编译选项
1
meson setup build -Dplatform=generic
编译
1
2
3
4cd build
ninja
meson install
ldconfig
DPDK 与网卡
官方实例
Hello World
编译运行
编译
1
2
3cd build
meson configure -Dexamples=helloworld
ninja运行
1
2echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
cd build1
2
3
4
5
6
7
8
9
10
11root@ubuntu:/opt/dpdk-23.11/build# ./examples/dpdk-helloworld
EAL: Detected CPU lcores: 3
EAL: Detected NUMA nodes: 1
EAL: Detected static linkage of DPDK
EAL: Multi-process socket /var/run/dpdk/rte/mp_socket
EAL: Selected IOVA mode 'PA'
EAL: VFIO support initialized
TELEMETRY: No legacy callbacks, legacy socket not created
hello from core 1
hello from core 2
hello from core 0
代码解析
建立一个多核(线程)运行环境,每个线程打印hello from core
1 | /* SPDX-License-Identifier: BSD-3-Clause |
示例
编译运行
编译
1
2
3cd build
meson configure -Dexamples=playground
ninja运行
1
./examples/dpdk-playground
rte 函数
rte_exit 退出函数
作用:退出中止程序
1 | void rte_exit(int exit_code, const char *format, ...) |
参数说明
exit_code: 退出状态码(0 表示成功,非零表示错误)一般使用 DPDK 提供的状态码
1
2
format: 格式化字符串(类似 printf)...: 可变参数,用于格式化字符串
使用示例
1 | int ret = rte_eal_init(argc, argv); |