GoLang基本语法
环境配置
配置环境变量,命令行输入
1
export PATH=/usr/local/go/bin:$PATH
此时可在命令行中使用
go命令新建一个
test.go文件1
2
3
4
5
6
7package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}在命令行中输入,即可运行
1
go run test.go
入门
go的基本结构和语法
一个简单的go程序:
1 | // 定义包 |
包声明
必须在非注释的第一行进行包声明
1
package main
每个Go应用程序都必须包含一个
main包引入包
1
import "fmt"
行分隔符
go中每一行代表一个语句结束,结尾不需要加像C那样加
;
输入输出
Printf 格式化字符串
使用fmt.Printf来格式化输出字符串
1 | fmt.Printf(格式化样式, 参数列表…) |
| 格 式 | 描 述 |
|---|---|
| %s | 字符串 |
| %f | 浮点数 |
| %d | 十进制整型 |
| %b | 二进制整型 |
| %o | 八进制整型 |
| %x | 十六进制整型 |
| %X | 十六进制整型,字母大写方式显示 |
1 | name := "John" |
输出:
John is 23
变量和常量
变量
变量名由字母、数字、下划线组成,其中首个字符不能为数字
使用 var 来声明变量
1 | var identifier type |
可以一次声明多个变量
1 | var identifier1, identifier2 type |
例如
1 | var str string = "Hello" |
如果没有初始化,则变量默认为零值
1 | package main |
输出:
0 0 false “”
可以根据值自行判断变量类型
1 | var str, num = "Hello", 1 |
可省略var,使用关键字:=
1 | str, num := "Hello", 1 |
常量
常量不会被修改,数据类型只可以是布尔型、数字型和字符串型。
1 | const identifier [type] = value |
因为可以通过value来判断数据类型,所有type可省略
显式表示
1
const str string = "abc"
隐式表示
1
const str = "abc"
可以一次声明多个常量
1 | const str, num = "Hello", 1 |
或者用枚举:
1 | const ( |
这里,a和b都是1,b会继承a的=1
iota
iota是一个可以被编译器修改的特殊常量,代表了位于const的第几行,如第 n 行 =iota 则为 n
1 | const ( |
数据结构
数组
概述
数组,是相同元素类型的集合。
数组由两个维度描述:
- 元素类型
- 最多存储的元素个数
只有这两个条件都相同的数组才是同一类型
初始化
访问和赋值
声明数组
1 | var variable_name [SIZE] variable_type |
示例:
1 | var nums [5] int |
初始化数组
1 | var nums = [5]int{1,2,3,4,5} |
1 | nums := [5]int{1, 2, 3, 4, 5} |
如果数组长度不确定,可以用...代替,编译器会根据元素个数自行推断数组的长度
1 | nums := [...]int{1, 2, 3, 4, 5} |
可以通过下标,只初始化特定的几个
1 | //初始化 nums[1] = 2.1 , nums[3] = 1.6 |
多维数组
以二维数组为例
1 | var arrayName [ x ][ y ] variable_type |
示例:
每行的结尾都要加,
1 | nums := [2][3]int{ |
或
1 | nums := [][]int{} |
数组作为函数参数
一维数组做参数:
设定数组大小
1
2
3func f1(nums [10]int) {
...
}未设定数组大小
1
2
3func f1(nums []int) {
...
}
指针
go中指针的规则与C类似
&用来取地址,*用来取内容
定义指针:
1 | var var_name *var-type |
空指针
当一个指针被定义后没有分配到任何变量时,即为一个空指针 nil
指针数组 & 数组指针
| 指针数组 | 数组指针 |
|---|---|
| 是一个数组 | 是一个指针 |
| 每个元素都是一个指针 | 指向一个数组 |
1 | n1, n2, n3 := 1, 2, 3 |
结构体
定义结构体
1 | type struct_variable_type struct { |
声明结构体变量
1 | variable_name := structure_variable_type {value1, value2...valuen} |
1 | variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen} |
通过 . 来访问结构体成员
示例:
1 | package main |
结构体指针
(与C不同)同样用 . 来访问结构体成员
1 | book_ptr := &book |
Slice 切片
与C++中的 vector 类似,长度不固定的动态数组,可以追加元素
定义切片
定义一个未指定大小的数组
1
var identifier []type
也可以使用 make() 函数来创建切片
1
slice1 := make([]type, len, capacity)
初始化切片
直接初始化切片,声明一个未指定大小的数组
1
s := []int{1,2,3}
通过引用数组/切片初始化切片
如有一数组/切片
arr,可以通过引用这个数组/切片来初始化切片引用全部的数组
1
s := arr[:]
引用从下标
startIndex到endIndex-1的部分1
s := arr[startIndex:endIndex]
引用从下标
startIndex到 最后一个元素 的部分1
s := arr[startIndex:]
引用从 第一个元素 到
endIndex-1的部分1
s := arr[:endIndex]
len() 和 cap()
len(s)获取切片长度cap(s)获取切片容量
1 | s := make([]int, 3, 5) |
append()
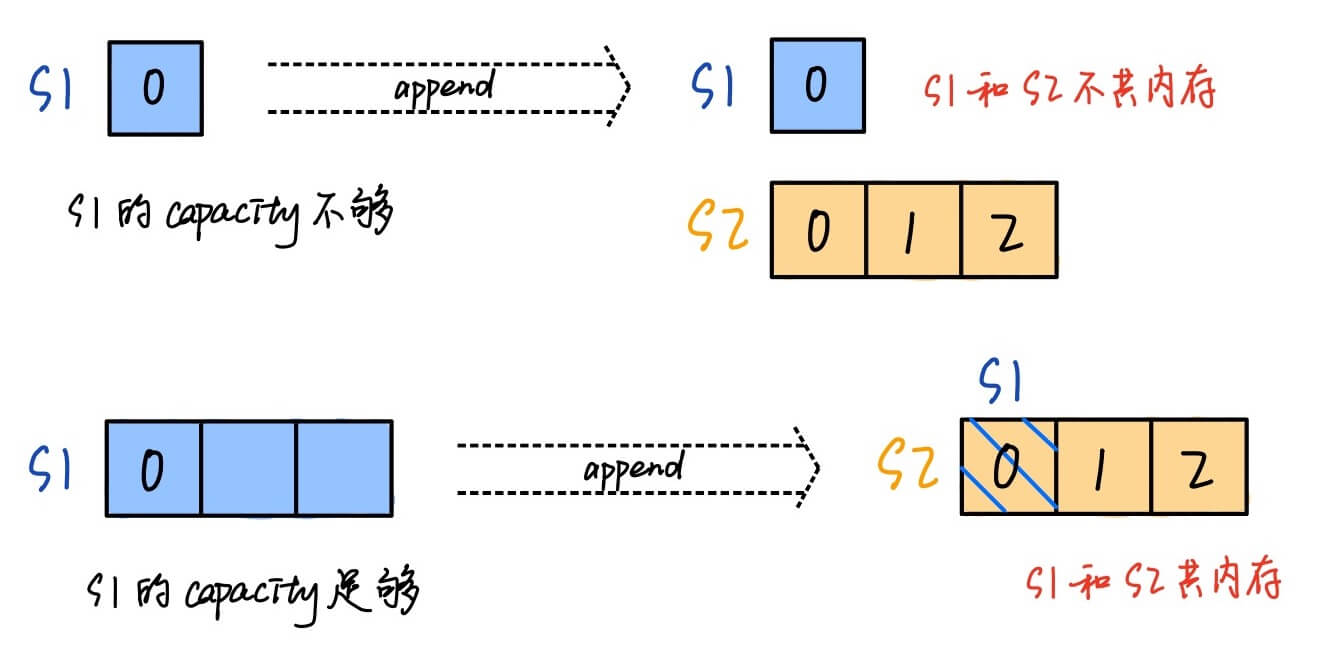
append扩展切片,原切片不变,返回的新切片在原切片上加上扩展项
1 | new_slice = append(old_slice []Type, elems ...Type) |
append()的原理:
如果 old slice 的 capacity够加,则 new slice 直接在 old slice 的内存上追加,共享内存;
如果capacity不够加,则 new slice 不与 old slice 共享内存,而是另开一片内存,复制 old slice 的数据
示例:
old slice 的 capacity 不够加
1 | s1 := []int{0} |
old slice 的 capacity 够加
1 | s1 := make([]int, 1, 3) |
copy()
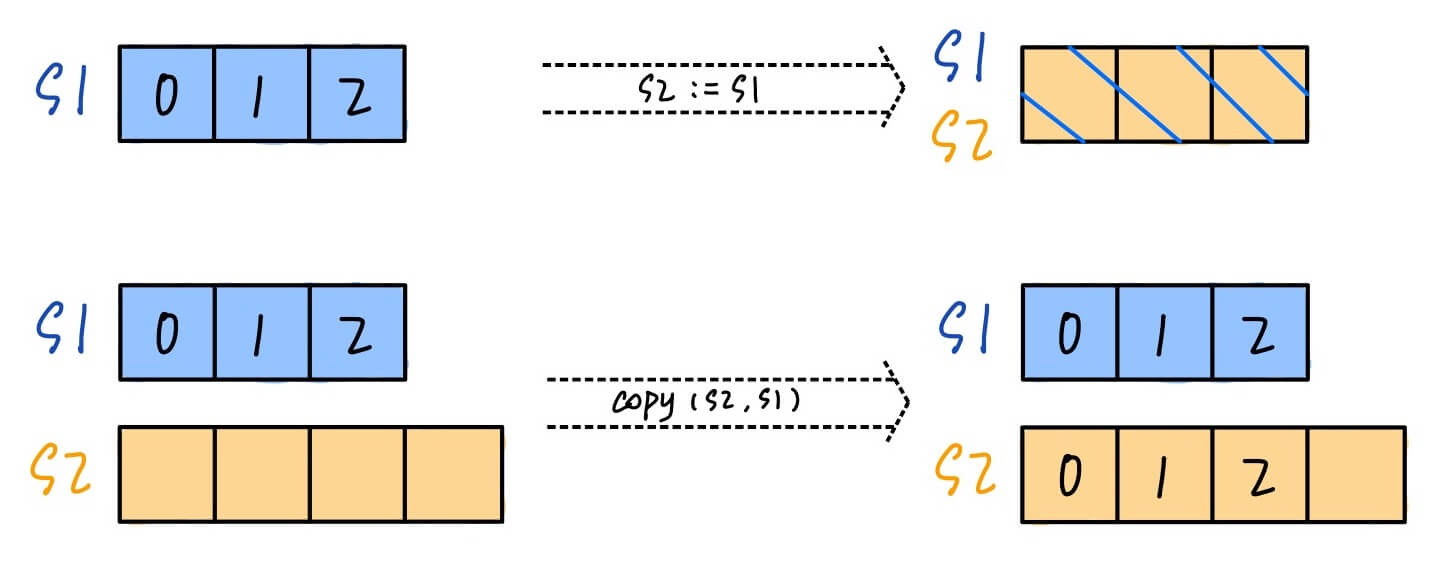
copy复制切片,必须创造一个比原切片 capacity 更大的新切片,才能复制过来
1 | copy(new_slice, old_slice) |
copy 和 = 的区别:
=赋值拷贝,会将原来slice的地址拷贝,新旧slice共享内存copy将slice内容进行拷贝,新旧slice不共享内存
1 | s1 := []int{0, 1, 2} |
Map 集合
无序的键值对,与C++中的map类似,但与C++中的map不同,
定义 Map
使用
make函数1
map_variable := make(map[KeyType]ValueType, initialCapacity)
initialCapacity可选填,用于指定 Map 的初始容量。Map 的容量是指 Map 中可以保存的键值对的数量。示例:
1
2
3
4
5// 创建一个空的 Map
m1 := make(map[string]int)
// 创建一个初始容量为 10 的 Map
m2 := make(map[string]int, 10)使用
map关键字1
2
3
4
5
6
7m1 := map[string]int{}
m2 := map[string]int{
"a": 1,
"b": 2,
"c": 3,
}
常用操作
获取元素
1
2
3v1 := m["a"]
v2, ok := m["d"] // 如果键不存在,v2为该类型的零值,ok=false修改元素
1
m["a"] = 2
删除元素
1
delete(m, "a")
获取长度
1
l := len(m)
遍历 map
1
2
3for k, v := range m {
...
}
控制结构
条件语句
if 语句
与C中类似,但是条件语句不需要用括号包住
1 | if condition1 { |
switch 语句
1 | switch expression { |
- 先执行
expression - 从上往下依次找匹配的 case
- go中的
switch默认自带break,匹配成功后,就不会执行其他 case - 如果希望匹配成功后继续执行后面的 case,可以使用
fallthrough
示例1:
1 | switch tag { |
示例2:
expression 可以为空
1 | switch { |
Type Switch
switch还可以用来判断某个 interface 变量中实际存储的变量类型
1 | var x interface{} |
fallthrough
如果在 case 的最后加上了 fallthrough,则无论紧接着的下一条 case 为 ture 还是 false,都会执行。
示例1:
1 | tag := 1 |
输出:
1
2
示例2:
1 | tag := 1 |
输出:
1
2
3
default
select 语句
select 类似于 switch,但是 select 只能用于通道操作
select会监听所有通道,一旦有通道准备好,就随机选择其中一个通道执行- 如果所有通道都没准备好,则执行
default - 如果没有
default,select将阻塞,直到某个通道可以运行
多个case匹配时,switch从上至下匹配第一个,select随机匹配一个
1 | select { |
示例:
1 | package main |
输出:
no message received
from 1
from 2
from 1
from 2
no message received
no message received
from 2
from 1
no message received
循环语句
for 语句
go的 for 语句有多种用法:
与C的
for相似的用法1
2
3for init; condition; post {
...
}与C的
while相似的用法只留下
condition项,则只需判断condition1
2
3for condition {
...
}与C的
while(1)相似的用法三项都不填,则无限循环
1
2
3for {
...
}range格式for循环的range格式可以对 slice、map、数组、字符串等进行迭代循环1
2
3for key, value := range oldMap {
newMap[key] = value
}也可以只提取
key或者value1
2
3for key := range oldMap {
...
}只提取
value时,需要用_,占掉key的位置1
2
3for _, value := range oldMap {
...
}
break
与C中的break用法相似,但多一个标号的功能:
在多重循环中,可以使用标号 label 跳出指定的循环。
示例:
不加标号时,与C一样,只会 break 掉最里面的那层循环
1 | package main |
输出:
i = 0, j = 0
i = 1, j = 0
i = 2, j = 0
加上标号后,会 break 掉标号的那层循环
1 | package main |
输出:
i = 0, j = 0
continue
与 break 一样,可以通过标号 label 指定需要 continue 的循环
函数
函数的定义
1 | func function_name( [parameter list] ) [return_types] { |
parameter list参数列表,选填,可以无参,格式为parameter_name1 type1, parameter_name2 type2, ...return_types返回类型,选填,可以无返回值(相当于C中的void),也可以返回多个值,格式为(type1, type2, ...)
示例1:
1 | func max(num1, num2 int) int { |
示例2:
1 | func swap(x, y string) (string, string) { |
1 | y, x := swap("hello", "world") |
引用传递参数
与C中的指针类似,传递地址指针
1 | func swap(x *int, y *int) { |
函数变量
1 | package main |
闭包
闭包包含两点:
存在函数外部定义,但在函数内部引用的自由变量
脱离了形成闭包的上下文,闭包也能照常使用这些自由变量,通常称这些自由变量为捕获变量
go语言中函数是头等对象,闭包可以充当C++中类的变量功能,也经常称闭包为有状态的函数
示例:
1 | package main |
getSequence返回一个闭包函数
变量i就是在闭包外定义,闭包内使用的变量
即使脱离了闭包的上下文,在main中,也可以调用nextNumber闭包函数,并使用定义在getSequence中的局部变量变量i
nextNumber1 := getSequence()和nextNumber2 := getSequence()分别独立,各自的捕获变量i不影响
方法
在其他语言中,函数和方法是一样的,但在go中有所区别
方法是一种有接收者的特殊函数,可以实现C++类的函数功能
接受者可以是命名类型或者结构体类型的一个值或者是一个指针
1 | func (variable_name variable_data_type) function_name() [return_type]{ |
variable_name接受者名variable_data_type接受者类型
示例:
1 | package main |
类型转换
数值类型转换
格式:
1 | type_name(expression) |
示例:
1 | var v1 int = 10 |
字符串类型转换
string 转 int
使用
strconv.Atoi将 string 转换为 int,第二个返回值为可能发生的错误,可以用_来忽略这个错误1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17package main
import (
"fmt"
"strconv"
)
func main() {
str := "10"
num, err := strconv.Atoi(str)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(num)
}
}int 转 string
使用
strconv.Itoa将 int 转换为 string1
2num := 10
str := strconv.Itoa(num)string 转 float
使用
strconv.ParseFloat将 string 转换为 float,第二个参数为 bitSize,用来选择究竟是64位还是32位的 float1
2str := "3.14"
num, err := strconv.ParseFloat(str, 64)
接口类型转换
接口
go 通过接口实现了C++中多态的效果。
接口把所有的具有共性的方法定义在一起
隐式实现,不用声明某个struct实现了那个接口,如果一个struct实现了一个接口定义的所有方法,那么它就自动地实现了该接口
1 | /* 定义接口 */ |
示例:
1 | package main |
定义一个 Sleeper 接口,Cat 和 Dog 都实现了Sleeper 接口的所有方法,所以隐式实现了接口。
如此 AnimalSleep() 函数实现了一个函数多个状态,也就是多态
错误处理
函数定义时,使用 errors.New 返回错误信息
1 | func Sqrt(f float64) (float64, error) { |
调用函数时,接收返回的错误信息err
1 | result, err:= Sqrt(-1) |
并发编程
goroutine 线程
goroutine 是轻量级线程,通过 go 关键字开启,如此可以同时多个线程并发进行。
同一个程序中的所有 goroutine 共享同一个地址空间。
格式:
1 | go func(x, y, z) |
如此,就开启了一个新的线程 func(x, y, z)
示例:
1 | package main |
输出:
drinking
eating
drinking
eating
eating
drinking
可以看出 eat 和 drink 两个线程并发执行,一下输出 eating,一下输出 drinking
channel 通道
通道是用来传递数据的一种数据结构,可用于两个 goroutine 之间通过传递值来同步运行和通讯
发送和接收
用 <- 来发送和接收数据
1 | ch <- value // 把 value 发送到通道 ch |
1 | v := <-ch // 从 ch 接收数据 |
1 | <-ch // 从 ch 接收数据 |
定义通道
利用 chan 关键字定义通道,使用 make 创建一个引用,当复制一个channel或用于函数参数传递时,实际只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象
不带缓冲区的通道(默认)
1
ch := make(chan int)
如此定义了一个不带缓冲区的通道,通道可以传递 int 参数
带缓冲区的通道
1
ch := make(chan int, 100)
如此定义了一个带缓冲区的通道,缓冲区大小为100
默认不带缓冲区,发送端发送数据,同时必须有接收端相应的接收数据。如果迟迟没有接收,发送方会阻塞直到接收方从通道中接收了值。
1 | package main |
带缓冲区的通道允许发送端和接收端异步,发送端可以先把数据放进缓存区内,发送端进程进行向下进行,不需要等待接收端接收。
但如果缓冲区满了,发送端同样会像不带缓冲区的通道那样卡住,直到有接收方从通道中接收了值。
1 | package main |
关闭通道
关闭通道后,不会再发送数据到通道上了
1 | close(ch) |
接收端在接收时,可以通过额外的第二个变量来判断通道是否关闭
1 | v, ok := <- ch |
遍历通道
与数组、切片相同,使用 range 关键字来遍历通道
1 | for v := range ch { |
规则:
- 遍历一个空的通道(nil)时,阻塞
- 遍历一个 阻塞 && 未关闭 的通道(nil)时,阻塞
- 遍历一个 阻塞 && 已关闭 的通道(nil)时,不做任何操作
- 遍历一个 非阻塞 && 未关闭 的通道(nil)时,接收所有缓存数据,然后阻塞
- 遍历一个 非阻塞 && 已关闭 的通道(nil)时,接收所有缓存数据,然后返回
上下文
问题记录
单引号、双引号、反引号
- 单引号
'':包裹字符 - 双引号
"":包裹字符串,会解析其中的转义符 - 反引号 ````:包裹字符串,不会解析其中的转义符
1 | fmt.Print("Hello, World!\n") //双引号,会解析其中的转义符 |
输出:
Hello, World!
Hello, World!\n%
Go modules
go modules 是 go 的依赖包管理工具
go 的包管理发展
在引入 go modules 之前,go 管理依赖包先是用 GOPATH,后来用 go vender
GOPATH
go path 理论上并不算是包管理工具,需要手动管理依赖包,写程序代码必须放在 $GOPATH/src 目录下,且依赖包没有版本可言
go vendor
解决了包管理问题,所有依赖包下载到项目的 vendor 目录下
go modules 的使用
首先要确定 go 语言的版本,至少需是 v1.11 以上版本
1 | go version |
环境设置
查看 go 的环境变量
1 | go env |
其中与 Go Modules 相关的环境设置如下
GO111MODULE
1 | go env -w GO111MODULE=on |